
I am writing a short survey on connections between additive combinatorics and computer science for SIGACT News and I have been wondering about the “history” of the connections. (I will be writing as little as possible about history in the SIGACT article, because I don’t have the time to research it carefully, but if readers help me out, I would write about it in a longer article that I plan to write sometime next year.)
Now, of course, there is always that Russian paper from the 1950s . . .
Then there is the Coppersmith-Winograd matrix multiplication algorithm, which uses Behrend’s construction of large sets of integers with no length-3 arithmetic progressions. (They don’t need the full strength of Behrend’s construction, and the weaker construction of Salem and Spencer suffices.) As far as I know, this was an isolated application.
My understanding (which is quite possibly mistaken) is that there are three main threads to the current interactions: one concerning the Szemeredi Regularity Lemma and the “triangle removal lemma” of Ruzsa and Szemeredi; one concerning “sum-product theorems” and the Kakeya problem; and one concerning the Gowers uniformity norms. The earliest connection is the first one, and, depending how one is counting, started in 1992 or 2001, and is due, respectively, to Alon et al. or just to Alon.
The Regularity Lemma, the Triangle Removal Lemma, and Graph Property Testing
The Szemeredi Regularity Lemma is a main technical tool in Szemeredi’s 1969 proof of Szemeredi’s theorem for progressions of length 4, and, eventually, his 1976 proof of the full 1975 proof of Szemeredi’s theorem. Rusza and Szemeredi, in a 1978 paper called “Triple systems with no six points carrying three triangles” showed that one could derive Roth’s Theorem (the length-3 case of Szemeredi’s theorem) as an simple consequence of a “Triangle Removal Lemma” (the derivation is simple but rather clever) which is itself a simple consequence of the Regularity Lemma. I have seen the Rusza-Szemeredi paper been referenced as either written in 1976 or 1978 – I never had a chance to see the paper itself. (More here about the Triangle Removal Lemma and Roth’s theorem.) Behrend had proved in the 1940s a negative result about the parameters in Roth’s theorem (before, indeed, Roth’s theorem was proved), which then, because of the Rusza-Szemeredi work, translates into a negative result about the parameters in the Triangle Removal Lemma: the lemma says that if we need to remove 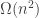



There were various paper in the 1990s on applications of the Regularity Lemma, and of variants of it, in computer science, starting, I think, with a 1992 paper by Alon, Duke, Lefmann, Rödl, and Yuster. Notably, Frieze and Kannan proved in 1996 that the Regularity Lemma could be used to provide approximation schemes for optimization problems on dense graphs. Motivated by this application, Frieze and Kannan then formulated and proved the Weak Regularity Lemma, a version of the result that gives a weaker form of partition, but with much better quantitative bounds.
Coming to the main connection, after Goldreich, Goldwasser and Ron introduced the notion of property testing in 1996, various people realized that the GGR notion of testing graph properties in the adjacency matrix model captured earlier work in extremal combinatorics. A 1999 paper by Alon, Fischer, Krivelevich, and Szegedy shows how to use the Szemeredi Regularity Lemma to design property testing algorithms, and I think it is the first paper of the kind.
Two years later, Alon studied the problem of testing the property of having a fixed graph 
The Rusza-Szemeredi argument has a natural analog that proves the full Szemeredi’s theorem, provided that one can prove a “clique removal lemma for hypergraphs,” which in turn one would want to derive from a properly formulated “Hypergraph Regularity Lemma.” This approach ended up being extremely difficult to follow, and such a proof was devised only a few years ago, independently by Nagle, Rödl, Schacht, and Skokan; by Gowers; and by Tao. This in turn has various applications to testing properties of dense hypergraphs, which have been studied by additive combinatorialists.
Kakeya Sets and Sum-Product Theorems
A Besicovitch set, or Kakeya set is a set that, for every direction, contains a unit-length segment parallel to that direction. The Kakeya problem is, roughly speaking, how “large” such a set must be. It is known that, for every 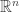
A particularly important turn of events started in1998, when Bourgain saw a way to make progress on this problem using one of the staples of additive combinatorics: an understanding of the structures of subsets 




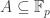




Meanwhile, one of Avi Wigderson’s favorite open problems was that of finding “seedless” randomness extractors for independent sources. (That’s quite the abrupt switch of topic, but bear with me.) There had been no progress on it since the 1985 paper by Chor and Goldreich which had introduced the problem. A while ago (the 1990s, I believe) Avi formulated the following question: suppose 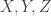



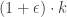
Bourgain, Katz and Tao proved in 2004 the Wolff finite field sum-product conjecture. (For sets
But the most surprising turn of events regarded the Kakeya problem itself: Zeev Dvir, a complexity theorist, found an absolutely stunning three-page proof of the Kakeya conjecture in finite fields. (Which is now, I guess, Dvir’s theorem.) Zeev’s proof, which uses simple properties of low-degree polynomials in finite fields (a staple of complexity theory) is very much a “computer science proof.”
Gowers Norms
This is the thread that I have been involved with, so it’s probably the one in which I’ll get the story mixed up the most.
At the end of the 1990s, Gowers found an analytic proof of Szemeredi’s theorem, which had much better quantitative parameters than the two previously known proofs: Szemeredi’s own, and Furstenberg’s ergodic theoretic proof. The main technical tool introduced by Gowers was a new norm, now called the Gowers uniformity norm, for functions whose domain is an abelian group. Expressions similar to the one that defined the Gowers norm had occurred before in ergodic theory, in work motivated by Furstenberg’s proof of Szemeredi’s theorem. (In recent years, there has been a lot of progress in understanding the connections between Gowers’s work and the related work in ergodic theory.)
Perhaps more surprisingly, a somewhat similar expression had appeared in a 1993 paper by Chung and Tetali on communication complexity in the number-on-the-forehead model. More closely related, in 2003 Alon, Kaufman, Krivelevich, Litsyn and Ron wrote a paper on testing low-degree multivariate polynomials over 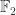
Meanwhile, Green and Tao had been applying the Gowers uniformity norm in their spectacular proof that the primes contain arbitrarily long arithmetic progressions, had started a research program aimed at proving bounds on the number of solutions in primes of various types of systems of linear equations (arithmetic progressions are a particular case of patterns expressible via liner equations), and had also turned their attention to achieving further quantitative improvements in Szemeredi’s theorem, by improving various parts of Gowers’s argument.
Both in their work on patterns in primes and their work on quantitative bounds in Szemeredi’s theorem, Green and Tao found that a required step was to prove that if a function has a noticeably large Gowers norm, then it correlated with a “low degree polynomial type” object. In the case of functions whose domain is 

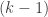
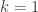
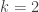
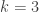
When the Green-Tao paper on primes in arithmetic progressions came out in 2004, I downloaded it with the same spirit in which I donwloaded Wiles’s paper when it came out. I wanted to hold a piece of mathematical history in my hands, and begin to read the introduction. I assumed that by the second sentence I wouldn’t know what they were talking about, and by the third sentence I wouldn’t know which words were supposed to be nouns and which words were supposed to be verbs. Instead I made it through the end of the introduction, and I was hooked, so I started going back to some of related earlier papers to gain a bit of background, which made me realize I had to go back to read even more background papers and so on. I had recently gotten tenure, so this was something that I could afford to do. Also I was impressed by the work of Avi and others using sum-product theorems (described above), and there was a sense that more connections could be discovered between additive combinatorics and computer science, and the equivalence between Gowers norm and the low-degree test of Alon and others was one of the things I noticed. I should mention that people without tenure were also studying this material and noticing these connections. Ryan O’Donnell, for example, wrote an expository note in August 2005 about additive combinatorics and computational complexity which mentioned the equivalence of Gowers norm and low-degree test, and all the other connections mentioned above.
Anyways, with a stunning synchronicity, just as I had downloaded the Green-Tao paper on the Gowers norm inverse conjecture, in April 2005 Alex Samorodnitsky sent me a preprint showing his result that if the quadratic low-degree test of Alon et al. has acceptance probability bounded away from 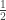

(About the remark on “integration:” Usually, low degree tests are analyzed in the following way: if the tested function 

Alex was wondering whether his test for quadratic polynomials could be turned into a PCP construction. (A few years earlier, we had worked on a joint paper on PCP.) My reply was: (1) congratulations for having proved the Gowers norm inverse conjecture for
After our work, there have been a few more occurrences of Gowers norm in complexity theory. Viola and Wigderson use the Gowers norm to prove “XOR lemmas” and “direct product theorems” in communication complexity and for low-degree polynomials. In communication complexity, they use the results of Chung and Tetali mentioned above. In studying correlation with low degree polynomials (see the article by Viola in the January issue of SIGACT News) they use the low-degree test of Alon and others.
Bogdanov and Viola construct a pseudorandom generator for low-degree polynomials which is conditional to the Gowers inverse conjecture; in order to fool degree-
Instead, Lovett and Viola simply make a careful use of induction and Cauchy–Schwarz. Indeed, my paper with Alex also just uses induction and Cauchy-Schwarz, in connection with some simple properties of the Gowers norm that themselves have proofs that come down to induction and Cauchy–Schwarz. (It would be interesting to see a way to abstract the use of such techniques, and find other places in computer science where they can be useful.)
This story has two more twists. First, Lovett, Meshulam and Samorodnitsky, and independently Green and Tao, show that the inverse conjecture for the 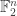
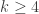
Then, most recently, Bergelson, Tao, and Ziegler have proved the Gowers norm inverse conjecture for every

Nice summary of the history!
Some minor comments. While this is neither additive combinatorics nor computer science, I think the theory of pseudorandom graphs (in particular, the ’89 paper of Chung-Graham-Wilson, and a slightly earlier paper of Thomason) is quite relevant to thread 1 (and, to some extent, to thread 3 also; Gowers’ norms were, I think, strongly influenced by the characterisation of pseudorandomness of graphs in terms of 4-cycles).
Szemeredi’s 1969 paper on 4-term progressions does not use the regularity lemma, which I think first appears in something resembling its modern form in the 1975 paper.
The Ruzsa-Szemeredi paper appeared in 1978, but was the proceedings for a conference held in 1976.
The finite field Kakeya conjecture was introduced by Wolff in his 1999 survey paper, essentially simultaneously with Bourgain’s paper. Tom Wolff also conjectured what is now the sum-product theorem for F_p, though this was a private communication.
My inverse U^3 paper with Ben doesn’t say this all too clearly, but our inverse results actually work for all groups G of odd order, including F_3^n; the only reason to avoid divisibility by 3 is when one turns to the applications involving length 4 progressions. By combining Samorodnitsky’s result on the even characteristic case with our result one should be able to get an inverse U^3 theorem for arbitrary finite abelian groups, though I don’t think anyone has bothered to write this down explicitly.
The paper of Tammy and myself connecting the infinitary inverse theorem to the finitary one in finite characteristic can be found here. (The low characteristic case is still being written up, it will probably take a few more months due to other priorities.)
Hi Terry, thanks for the comments and corrections!
If you’re looking for even the very very minor and isolated examples, I had a paper in SIGACT News 1987 that used sequences of integers with distinct sums of triples as part of an NP-completeness proof. It at least has the benefit of being earlier than the 1992 starting date you mention for the influence of these ideas within TCS.
And an even earlier application is due to Chandra-Furst-Lipton (STOC ’83) who used Behrend’s construction to devise a very clever protocol for a certain problem in the number-on-the-forehead model of communication.