Scribed by Anupam Prakash
Summary
Today we finish the analysis of a construction of a pseudorandom permutation (block cipher) given a pseudorandom function.

Scribed by Anupam Prakash
Summary
Today we finish the analysis of a construction of a pseudorandom permutation (block cipher) given a pseudorandom function.
Scribed by Siu-Man Chan
Summary
Given one way permutations (of which discrete logarithm is a candidate), we know how to construct pseudorandom functions. Today, we are going to construct pseudorandom permutations (block ciphers) from pseudorandom functions.
Today we finish the analysis of a construction of a pseudorandom permutation (block cipher) given a pseudorandom function.
Summary
Today we give a construction of a pseudorandom permutation (block cipher) given a pseudorandom function, and we begin its analysis. Continue reading
Scribed by Ian Haken
Summary
The encryption scheme we saw last time, based on pseudorandom functions, works and is CPA-secure, but it is not used in practice. A disadvantage of the scheme is that the length of the encryption is twice the length of the message being sent.
Today we see the “counter mode” generalization of that scheme, which has considerably smaller overhead for long messages, and see that this preserves CPA-security.
We then give the definition of pseudorandom permutation, which is a rigorous formalization of the notion of block cipher from applied cryptography, and see two ways of using block ciphers to perform encryption. One is totally insecure (ECB), the other (CBC) achieves CPA security.
1. The Randomized Counter Mode
Recall that a pseudorandom function is a function 

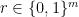

Suppose we have a pseudorandom function 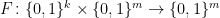





 :
:


(When 
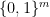



Observe that the ciphertext length is 
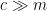
Theorem 1 Suppose
is a
-secure pseudorandom function; then, when used to encrypt messages of length
-CPA secure.
Example 1 Consider the values which these variables might take in the transmission of a large (e.g.
4GB) file. If we let
,
,
,
, then we end up with an approximately
-CPA secure transmission.
Proof: Recall the proof from last time in which we defined 

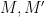

![{\mathop{\mathbb P}_K[ T^{Enc(K,\cdot)}(Enc(K,M)) = 1 ]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+P%7D_K%5B+T%5E%7BEnc%28K%2C%5Ccdot%29%7D%28Enc%28K%2CM%29%29+%3D+1+%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\mathop{\mathbb P}_R[ T^{\overline{Enc}(R,\cdot)}(\overline{Enc}(R,M)) = 1]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+P%7D_R%5B+T%5E%7B%5Coverline%7BEnc%7D%28R%2C%5Ccdot%29%7D%28%5Coverline%7BEnc%7D%28R%2CM%29%29+%3D+1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\mathop{\mathbb P}_R[ T^{\overline{Enc}(R,\cdot)}(\overline{Enc}(R,M')) = 1]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+P%7D_R%5B+T%5E%7B%5Coverline%7BEnc%7D%28R%2C%5Ccdot%29%7D%28%5Coverline%7BEnc%7D%28R%2CM%27%29%29+%3D+1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\mathop{\mathbb P}_K[ T^{Enc(K,\cdot)}(Enc(K,M')) = 1]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+P%7D_K%5B+T%5E%7BEnc%28K%2C%5Ccdot%29%7D%28Enc%28K%2CM%27%29%29+%3D+1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
We were able to show in the previous proof that 
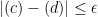
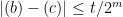

We will first show that for any
hence showing 
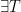
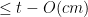
Define 



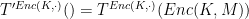
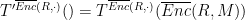
Now we want to show that 
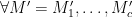
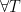
![{\left| \mathop{\mathbb P}_R[ T^{\overline{Enc}(R,\cdot)}(\overline{Enc}(R,M)) = 1] -\mathop{\mathbb P}_R[ T^{\overline{Enc}(R,\cdot)}(\overline{Enc}(R,M')) = 1] \right| \le 2ct/2^m}](https://s0.wp.com/latex.php?latex=%7B%5Cleft%7C+%5Cmathop%7B%5Cmathbb+P%7D_R%5B+T%5E%7B%5Coverline%7BEnc%7D%28R%2C%5Ccdot%29%7D%28%5Coverline%7BEnc%7D%28R%2CM%29%29+%3D+1%5D+-%5Cmathop%7B%5Cmathbb+P%7D_R%5B+T%5E%7B%5Coverline%7BEnc%7D%28R%2C%5Ccdot%29%7D%28%5Coverline%7BEnc%7D%28R%2CM%27%29%29+%3D+1%5D+%5Cright%7C+%5Cle+2ct%2F2%5Em%7D&bg=ffffff&fg=000000&s=0&c=20201002)
As in the previous proof, we consider the requests 








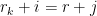

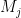


Note that the 

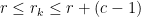
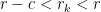
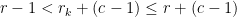

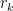

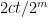
Combining these results, we see that 
![{\left| \mathop{\mathbb P}_K[ T^{Enc(K,\cdot)}(Enc(K,M)) = 1 ] - \mathop{\mathbb P}_K[ T^{Enc(K,\cdot)}(Enc(K,M')) = 1 ] \right| = O(\epsilon+ct/2^m)}](https://s0.wp.com/latex.php?latex=%7B%5Cleft%7C+%5Cmathop%7B%5Cmathbb+P%7D_K%5B+T%5E%7BEnc%28K%2C%5Ccdot%29%7D%28Enc%28K%2CM%29%29+%3D+1+%5D+-+%5Cmathop%7B%5Cmathbb+P%7D_K%5B+T%5E%7BEnc%28K%2C%5Ccdot%29%7D%28Enc%28K%2CM%27%29%29+%3D+1+%5D+%5Cright%7C+%3D+O%28%5Cepsilon%2Bct%2F2%5Em%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
◻
2. Pseudorandom Permutations
2.1. Some Motivation
Suppose the message stream has known messages, such as a protocol which always has a common header. For example, suppose Eve knows that Bob is sending an email to Alice, and that the first block of the message 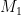


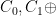

2.2. Definition
Denote by 

Definition 2 A pair of functions
,
is a
- For every
, the functions
and
are permutations (i.e. bijections) and are inverses of each other.
- For every oracle algorithm
![{\left| \mathop{\mathbb P}_K [T^{F_K,I_K}() = 1 ] - \mathop{\mathbb P}_{P \in \mathcal{P}_n}[T^{P,P^{-1}}() = 1 ] \right| \le \epsilon}](https://s0.wp.com/latex.php?latex=%7B%5Cleft%7C+%5Cmathop%7B%5Cmathbb+P%7D_K+%5BT%5E%7BF_K%2CI_K%7D%28%29+%3D+1+%5D+-+%5Cmathop%7B%5Cmathbb+P%7D_%7BP+%5Cin+%5Cmathcal%7BP%7D_n%7D%5BT%5E%7BP%2CP%5E%7B-1%7D%7D%28%29+%3D+1+%5D+%5Cright%7C+%5Cle+%5Cepsilon%7D&bg=ffffff&fg=000000&s=0&c=20201002)
That is, to any algorithm 

In applied cryptography literature, pseudorandom permutations are called block ciphers.
How do we construct pseudorandom permutations? There are a number of block cipher proposals, including the AES standard, that have been studied extensively and are considered safe for the time being. We shall prove later that any construction of pseudorandom functions can be turned into a construction of pseudorandom permutations; also, every construction of pseudorandom generators can be turned into a pseudorandom function, and every one-way function can be used to construct a pseudorandom generator. Ultimately, this will mean that it is possible to construct a block cipher whose security relies, for example, on the hardness of factoring random integers. Such a construction, however, would not be practical.
3. Encryption Using Pseudorandom Permutations
Here are two ways of using Pseudorandom Functions and Permutations to perform encryption. Both are used in practice.
3.1. ECB Mode
The Electronic Code-Book mode of encryption works as follows


Exercise 1 Show that ECB is message-indistinguishable for one-time encryption but not for two encryptions.
3.2. CBC Mode
In its simplest instantiation the Cipher Block-Chaining mode works as follows:
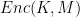 : pick a random string
: pick a random string  , output
, output 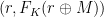
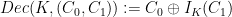
Note that this similar to (but a bit different from) the scheme based on pseudorandom functions that we saw last time. In CBC, we take advantage of the fact that 

There is a generalization in which one can use the same random string to send several messages. (It requires synchronization and state information.)
 :
:

 where
where 
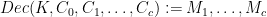 where
where 
Exercise 2 This mode achieves CPA security.
Note that CBC overcomes the above problem in which Eve knows a particular block of the message being sent, for if Eve modified 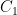
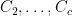
Summary
The encryption scheme we saw last time, based on pseudorandom functions, works and is CPA-secure, but it is not used in practice. A disadvantage of the scheme is that the length of the encryption is twice the length of the message being sent.
Today we see the “counter mode” generalization of that scheme, which has considerably smaller overhead for long messages, and see that this generalizes preserves CPA-security.
We then give the definition of pseudorandom permutation, which is a rigorous formalization of the notion of block cipher from applied cryptography, and see two ways of using block ciphers to perform encryption. One is totally insecure, the other achieves CPA security.
1. The Randomized Counter Mode
Suppose we have a pseudorandom function 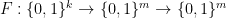
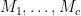
 :
:
 ;
;


(When 
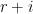
Theorem 1 Suppose
-secure against CPA
2. Pseudorandom Permutations
Denote by 

Definition 2 (Pseudorandom Permutation) A pair of functions

is a
-secure pseudorandom permutation if:
- For every
, the functions
and
are permutations and are one the inverse of the other;
- For every oracle algorithm
oracle queries we have
That is, without knowing the random key
In the applied cryptography literature, pseudorandom permutations are called block ciphers.
How do we construct pseudorandom permutations? There are a number of block ciphers proposal, including the AES standard, that have been studied extensively and are considered safe for the time being. We shall prove later that any construction of pseudorandom functions can be turned into a construction of pseudorandom permutations; also, every construction of pseudorandom generators can be turned into a pseudorandom function, and every one-way function can be used to construct a pseudorandom generator. Ultimately, this will mean that it is possible to construct a block cipher whose security relies, for example, on the hardness of factoring random integers. Such a construction, however, would not be practical.
3. Encryption Using Pseudorandom Permutations
Here are two ways of using Pseudorandom Functions and Permutations to perform encryption. Both are used in practice.
3.1. ECB Mode
The Electronic Code-Book mode of encryption works as follows
Exercise 1 Show that ECB is message-indistinguishable for one-time encryption but not for two encryptions.
3.2. CBC Mode
In its simplest instantiation the Cipher Block-Chaining mode works as follows:
 pick a random string
pick a random string  , output
, output 

Note that this similar to (but a bit different from) the scheme based on pseudorandom functions that we saw last time. In CBC, we take advantage of the fact that 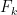
There is a generalization in which one can use the same random string to send several messages. (It requires synchronization and state information.)

 ;
;
 where
where 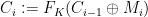
 where
where 
This mode achieves CPA security.
4. The Ultimate Security
CPA security is not yet the strongest possible definition of security. It does not capture the possibility that an active adversary might obtain plaintext-ciphertext pairs in which the ciphertext depends arbitrarily on the challenge that the adversary is trying to decode. Suppose that the encryption scheme is part of a larger protocol in which sender and receiver are expected to exchange messages in a certain format. Then the attacker can send a ciphertext (of which it does not know the decoding), and then see whether it receives a short reply (indicative that it is the encryption of “message invalid”) or a longer one (which would be the continuation of the protocol).
In a chosen ciphertext attack (CCA), an attacker is allowed to gain decodings of ciphertexts of her choice. A system is secure if, for any two messages
Definition 3 (CCA Security) An encryption scheme
is
- has complexity
;
- when given input
and oracles
,
never queries oracle
with the string
We have
It is not hard to show that all the encryption schemes we have seen so far fail CCA security.
Instead of trying to tweak the schemes in order to try and gain CCA security, we shall adopt a more modular design approach.
First, we will move on to discuss message authentication, which is an important goal in itself, for example when communicating with your online banking system. Then, we shall see that a CPA-secure encryption scheme, augmented with a proper message authentication scheme, automatically guarantees CCA security, because an attacker can never make any use of a decryption oracle.

![\displaystyle \left| \mathop{\mathbb P}_K[ T^{Enc(K,\cdot)}(Enc(K,M)) = 1 ] - \mathop{\mathbb P}_R[ T^{\overline{Enc}(R,\cdot)}(\overline{Enc}(R,M)) = 1 ] \right| \le \epsilon](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cleft%7C+%5Cmathop%7B%5Cmathbb+P%7D_K%5B+T%5E%7BEnc%28K%2C%5Ccdot%29%7D%28Enc%28K%2CM%29%29+%3D+1+%5D+-+%5Cmathop%7B%5Cmathbb+P%7D_R%5B+T%5E%7B%5Coverline%7BEnc%7D%28R%2C%5Ccdot%29%7D%28%5Coverline%7BEnc%7D%28R%2CM%29%29+%3D+1+%5D+%5Cright%7C+%5Cle+%5Cepsilon+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \left| \mathop{\mathbb P}_K[ T^{Enc(K,\cdot)}(Enc(K,M)) = 1 ] - \mathop{\mathbb P}_R[ T^{\overline{Enc}(R,\cdot)}(\overline{Enc}(R,M)) = 1 ] \right| > \epsilon](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cleft%7C+%5Cmathop%7B%5Cmathbb+P%7D_K%5B+T%5E%7BEnc%28K%2C%5Ccdot%29%7D%28Enc%28K%2CM%29%29+%3D+1+%5D+-+%5Cmathop%7B%5Cmathbb+P%7D_R%5B+T%5E%7B%5Coverline%7BEnc%7D%28R%2C%5Ccdot%29%7D%28%5Coverline%7BEnc%7D%28R%2CM%29%29+%3D+1+%5D+%5Cright%7C+%3E+%5Cepsilon+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle | \mathop{\mathbb P}_{K \in \{ 0,1 \}^k} [ T^{F_K,I_K} () =1 ] - \mathop{\mathbb P}_{P \in {\cal P}_n} [T^{P,P^{(-1)}} () = 1] | \leq \epsilon](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7C+%5Cmathop%7B%5Cmathbb+P%7D_%7BK+%5Cin+%5C%7B+0%2C1+%5C%7D%5Ek%7D+%5B+T%5E%7BF_K%2CI_K%7D+%28%29+%3D1+%5D+-+%5Cmathop%7B%5Cmathbb+P%7D_%7BP+%5Cin+%7B%5Ccal+P%7D_n%7D+%5BT%5E%7BP%2CP%5E%7B%28-1%29%7D%7D+%28%29+%3D+1%5D+%7C+%5Cleq+%5Cepsilon+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle | \mathop{\mathbb P} [ T^{Enc(K,\cdot),Dec(K,\cdot)} (Enc(K,M)) = 1]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7C+%5Cmathop%7B%5Cmathbb+P%7D+%5B+T%5E%7BEnc%28K%2C%5Ccdot%29%2CDec%28K%2C%5Ccdot%29%7D+%28Enc%28K%2CM%29%29+%3D+1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle - \mathop{\mathbb P} [ T^{Enc(K,\cdot),Dec(K,\cdot)} (Enc(K,M')) = 1] | \leq \epsilon](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++-+%5Cmathop%7B%5Cmathbb+P%7D+%5B+T%5E%7BEnc%28K%2C%5Ccdot%29%2CDec%28K%2C%5Ccdot%29%7D+%28Enc%28K%2CM%27%29%29+%3D+1%5D+%7C+%5Cleq+%5Cepsilon+&bg=ffffff&fg=000000&s=0&c=20201002)
