We want to prove that a dense subset of a pseudorandom set is indistinguishable from a truly dense set.
Here is an example of what this implies: take a pseudorandom generator of output length  , choose in an arbitrary way a 1% fraction of the possible seeds of the generator, and run the generator on a random seed from this restricted set; then the output of the generator is indistinguishable from being a random element of a set of size
, choose in an arbitrary way a 1% fraction of the possible seeds of the generator, and run the generator on a random seed from this restricted set; then the output of the generator is indistinguishable from being a random element of a set of size 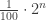 .
.
(Technically, the theorem states the existence of a distribution of min-entropy  , but one can also get the above statement by standard “rounding” techniques.)
, but one can also get the above statement by standard “rounding” techniques.)
As a slightly more general example, if you have a generator  mapping a length-
mapping a length- seed into an output of length , and
seed into an output of length , and  is a distribution of seeds of min-entropy at least
is a distribution of seeds of min-entropy at least  , then
, then 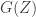 is indistinguishable from a distribution of min-entropy
is indistinguishable from a distribution of min-entropy 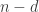 . (This, however, works only if
. (This, however, works only if 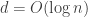 .)
.)
It’s time to give a formal statement. Recall that we say that a distribution  is
is  -dense in a distribution
-dense in a distribution  if
if
![\forall x. Pr[R=x] \geq \delta \cdot Pr [D=x]](https://s0.wp.com/latex.php?latex=%5Cforall+x.+Pr%5BR%3Dx%5D+%5Cgeq+%5Cdelta+%5Ccdot+Pr+%5BD%3Dx%5D&bg=ffffff&fg=333333&s=0&c=20201002)
(Of course I should say “random variable” instead of “distribution,” or write things differently, but we are between friends here.)
We want to say that if  is a class of tests, is pseudorandom according to a moderately larger class
is a class of tests, is pseudorandom according to a moderately larger class 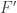 , and is -dense in , then there is a distribution
, and is -dense in , then there is a distribution  that is indistinguishable from according to and that is -dense in the uniform distribution.
that is indistinguishable from according to and that is -dense in the uniform distribution.
The Green-Tao-Ziegler proof of this result becomes slightly easier in our setting of interest (where contains boolean functions) and gives the following statement:
Theorem (Green-Tao-Ziegler, Boolean Case)
Let  be a finite set, be a class of functions
be a finite set, be a class of functions  , be a distribution over , be a -dense distribution in ,
, be a distribution over , be a -dense distribution in ,  be given.
be given.
Suppose that for every that is -dense in 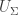 there is an
there is an 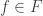 such that
such that
![| Pr[f(D)=1] - Pr[f(M)] = 1| >\epsilon](https://s0.wp.com/latex.php?latex=%7C+Pr%5Bf%28D%29%3D1%5D+-+Pr%5Bf%28M%29%5D+%3D+1%7C+%3E%5Cepsilon&bg=ffffff&fg=333333&s=0&c=20201002)
Then there is a function  of the form
of the form 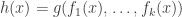 where
where 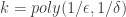 and
and  such that
such that
![| Pr [h(R)=1] - Pr [ h(U_\Sigma) =1] | > poly(\epsilon,\delta)](https://s0.wp.com/latex.php?latex=%7C+Pr+%5Bh%28R%29%3D1%5D+-+Pr+%5B+h%28U_%5CSigma%29+%3D1%5D+%7C+%3E+poly%28%5Cepsilon%2C%5Cdelta%29&bg=ffffff&fg=333333&s=0&c=20201002)
Readers should take a moment to convince themselves that the above statement is indeed saying that if is pseudorandom then has a model , by equivalently saying that if no model exists then is not pseudorandom.
The problem with the above statement is that  can be arbitrary and, in particular, it can have circuit complexity exponential in
can be arbitrary and, in particular, it can have circuit complexity exponential in  , and hence in
, and hence in  .
.
In our proof, instead, is a linear threshold function, realizable by a  size circuit. Another improvement is that
size circuit. Another improvement is that  .
.
Here is the proof by Omer Reingold, Madhur Tulsiani, Salil Vadhan, and me. Assume is closed under complement (otherwise work with the closure of ), then the assumption of the theorem can be restated without absolute values
for every that is -dense in there is an such that
![Pr[f(D)=1] - Pr[f(M) = 1] >\epsilon](https://s0.wp.com/latex.php?latex=Pr%5Bf%28D%29%3D1%5D+-+Pr%5Bf%28M%29+%3D+1%5D+%3E%5Cepsilon&bg=ffffff&fg=333333&s=0&c=20201002)
We begin by finding a “universal distinguisher.”
Claim
There is a function ![\bar f:\Sigma \rightarrow [0,1]](https://s0.wp.com/latex.php?latex=%5Cbar+f%3A%5CSigma+%5Crightarrow+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) which is a convex combination of functions from and such that that for every that is -dense in ,
which is a convex combination of functions from and such that that for every that is -dense in ,
![E[\bar f(D)] - E[\bar f(M)] >\epsilon](https://s0.wp.com/latex.php?latex=E%5B%5Cbar+f%28D%29%5D+-+E%5B%5Cbar+f%28M%29%5D++%3E%5Cepsilon&bg=ffffff&fg=333333&s=0&c=20201002)
This can be proved via the min-max theorem for two-players games, or, equivalently, via linearity of linear programming, or, like an analyst would say, via the Hahn-Banach theorem.
Let now  be the set of
be the set of 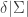 elements of where
elements of where  is largest. We must have
is largest. We must have
(1) ![E[\bar f(D)] - E[\bar f(U_S)] >\epsilon](https://s0.wp.com/latex.php?latex=E%5B%5Cbar+f%28D%29%5D+-+E%5B%5Cbar+f%28U_S%29%5D+%3E%5Cepsilon&bg=ffffff&fg=333333&s=0&c=20201002)
which implies that there must be a threshold such that
(2) ![Pr[\bar f(D)\geq t] - Pr[\bar f(U_S) \geq t] >\epsilon](https://s0.wp.com/latex.php?latex=Pr%5B%5Cbar+f%28D%29%5Cgeq+t%5D+-+Pr%5B%5Cbar+f%28U_S%29+%5Cgeq+t%5D++%3E%5Cepsilon&bg=ffffff&fg=333333&s=0&c=20201002)
So we have found a boolean distinguisher between and 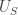 . Next,
. Next,
we claim that the same distinguisher works between and .
By the density assumption, we have
![Pr[\bar f(R)\geq t] \geq \delta \cdot Pr[\bar f(D) \geq t]](https://s0.wp.com/latex.php?latex=Pr%5B%5Cbar+f%28R%29%5Cgeq+t%5D+%5Cgeq+%5Cdelta+%5Ccdot+Pr%5B%5Cbar+f%28D%29+%5Cgeq+t%5D&bg=ffffff&fg=333333&s=0&c=20201002)
and since contains exactly a fraction of , and since the condition 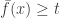 always fails outside of (why?), we then have
always fails outside of (why?), we then have
![Pr[\bar f(U_\Sigma)\geq t] = \delta \cdot Pr[\bar f(U_S) \geq t]](https://s0.wp.com/latex.php?latex=Pr%5B%5Cbar+f%28U_%5CSigma%29%5Cgeq+t%5D+%3D+%5Cdelta+%5Ccdot+Pr%5B%5Cbar+f%28U_S%29+%5Cgeq+t%5D&bg=ffffff&fg=333333&s=0&c=20201002)
and so
(3) ![Pr[\bar f(R)\geq t] - Pr[\bar f(U_\Sigma) \geq t] >\delta \epsilon](https://s0.wp.com/latex.php?latex=Pr%5B%5Cbar+f%28R%29%5Cgeq+t%5D+-+Pr%5B%5Cbar+f%28U_%5CSigma%29+%5Cgeq+t%5D++%3E%5Cdelta+%5Cepsilon+&bg=ffffff&fg=333333&s=0&c=20201002)
Now, it’s not clear what the complexity of is: it could be a convex combination involving all the functions in . However, by Chernoff bounds, there must be functions  with such that
with such that 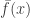 is well approximated by
is well approximated by  for all $x$ but for an exceptional set having density less that, say,
for all $x$ but for an exceptional set having density less that, say,  , according to both and .
, according to both and .
Now and are distinguished by the predicate 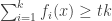 , which is just a linear threshold function applied to a small set of functions from , as promised.
, which is just a linear threshold function applied to a small set of functions from , as promised.
Actually I have skipped an important step: outside of the exceptional set,  is going to be close to but not identical, and this could lead to problems. For example, in (3)
is going to be close to but not identical, and this could lead to problems. For example, in (3) 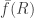 might typically be larger than only by a tiny amount, and might consistently underestimate in . If so,
might typically be larger than only by a tiny amount, and might consistently underestimate in . If so, ![Pr [ \sum_{i=1}^k f_i(R) \geq tk ]](https://s0.wp.com/latex.php?latex=Pr+%5B+%5Csum_%7Bi%3D1%7D%5Ek+f_i%28R%29+%5Cgeq+tk+%5D&bg=ffffff&fg=333333&s=0&c=20201002) could be a completely different quantity from
could be a completely different quantity from ![Pr [\bar f(R)\geq t]](https://s0.wp.com/latex.php?latex=Pr+%5B%5Cbar+f%28R%29%5Cgeq+t%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.
To remedy this problem, we note that, from (1), we can also derive the more “robust” distinguishing statement
(2′) ![Pr[\bar f(D)\geq t+\epsilon/2] - Pr[\bar f(U_S) \geq t] >\epsilon/2](https://s0.wp.com/latex.php?latex=Pr%5B%5Cbar+f%28D%29%5Cgeq+t%2B%5Cepsilon%2F2%5D+-+Pr%5B%5Cbar+f%28U_S%29+%5Cgeq+t%5D++%3E%5Cepsilon%2F2&bg=ffffff&fg=333333&s=0&c=20201002)
from which we get
(3′) ![Pr[\bar f(R)\geq t+\epsilon/2] - Pr[\bar f(U_\Sigma) \geq t] >\delta \epsilon/2](https://s0.wp.com/latex.php?latex=Pr%5B%5Cbar+f%28R%29%5Cgeq+t%2B%5Cepsilon%2F2%5D+-+Pr%5B%5Cbar+f%28U_%5CSigma%29+%5Cgeq+t%5D++%3E%5Cdelta+%5Cepsilon%2F2+&bg=ffffff&fg=333333&s=0&c=20201002)
And now we can be confident that even replacing with an approximation we still get a distinguisher.
The statement needed in number-theoretic applications is stronger in a couple of ways. One is that we would like to contain bounded functions ![f:\Sigma \rightarrow [0,1]](https://s0.wp.com/latex.php?latex=f%3A%5CSigma+%5Crightarrow+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) rather than boolean-valued functions. Looking back at our proof, this makes no difference. The other is that we would like
rather than boolean-valued functions. Looking back at our proof, this makes no difference. The other is that we would like 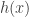 to be a function of the form
to be a function of the form 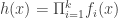 rather than a general composition of functions
rather than a general composition of functions  . This we can achieve by approximating a threshold function by a polynomial of degree
. This we can achieve by approximating a threshold function by a polynomial of degree 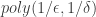 using the Weierstrass theorem, and then choose the most distinguishing monomial. This gives a proof of the following statement, which is equivalent to Theorem 7.1 in the Tao-Ziegler paper.
using the Weierstrass theorem, and then choose the most distinguishing monomial. This gives a proof of the following statement, which is equivalent to Theorem 7.1 in the Tao-Ziegler paper.
Theorem (Green-Tao-Ziegler, General Case)
Let be a finite set, be a class of functions ![f:\Sigma \to [0,1]](https://s0.wp.com/latex.php?latex=f%3A%5CSigma+%5Cto+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) , be a distribution over , be a -dense distribution in , be given.
, be a distribution over , be a -dense distribution in , be given.
Suppose that for every that is -dense in there is an such that
Then there is a function of the form where and such that
![| Pr [f(R)=1] - Pr [ f(U_\Sigma) =1] | > exp(-poly(1/\epsilon,1/\delta))](https://s0.wp.com/latex.php?latex=%7C+Pr+%5Bf%28R%29%3D1%5D+-+Pr+%5B+f%28U_%5CSigma%29+%3D1%5D+%7C+%3E+exp%28-poly%281%2F%5Cepsilon%2C1%2F%5Cdelta%29%29&bg=ffffff&fg=333333&s=0&c=20201002)
In this case, we too lose an exponential factor. Our proof, however, has some interest even in the number-theoretic setting because it is somewhat simpler than and genuinely different from the original one.



 in complexity-theoretic applications or
in complexity-theoretic applications or  in number-theoretic applications. Instead of working with subsets of
in number-theoretic applications. Instead of working with subsets of ![f: \Sigma \rightarrow [0,1]](https://s0.wp.com/latex.php?latex=f%3A+%5CSigma+%5Crightarrow+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . In a complexity-theoretic applications, this could be the set of boolean functions computed by circuits of bounded size. We think of two distributions
. In a complexity-theoretic applications, this could be the set of boolean functions computed by circuits of bounded size. We think of two distributions 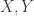 as being
as being  -indistinguishable according to
-indistinguishable according to ![| E [f(X)] - E[f(Y)] | \leq \epsilon](https://s0.wp.com/latex.php?latex=%7C+E+%5Bf%28X%29%5D+-+E%5Bf%28Y%29%5D+%7C+%5Cleq+%5Cepsilon&bg=ffffff&fg=333333&s=0&c=20201002)
 is
is  if for every
if for every  we have
we have![Pr [ B=x] \geq \delta Pr [A=x]](https://s0.wp.com/latex.php?latex=Pr+%5B+B%3Dx%5D+%5Cgeq+%5Cdelta+Pr+%5BA%3Dx%5D&bg=ffffff&fg=333333&s=0&c=20201002)
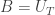 and
and  for some sets
for some sets 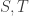 , then
, then 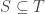 and
and  .
.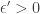 such that if
such that if  -pseudorandom distribution according to
-pseudorandom distribution according to  , then
, then  and
and 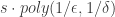 . Unfortunately, if one follows the proof and makes some simplifications asuming
. Unfortunately, if one follows the proof and makes some simplifications asuming  , where
, where  could be arbitrary and, in general, have circuit complexity exponential in
could be arbitrary and, in general, have circuit complexity exponential in 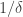 . Alternatively one may approximate
. Alternatively one may approximate 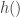 as a low-degree polynomial and take the “most distinguishing monomial.” This will give a version of the Theorem (which leads to the actual statement of Thm 7.1 in the Tao-Ziegler paper) where
as a low-degree polynomial and take the “most distinguishing monomial.” This will give a version of the Theorem (which leads to the actual statement of Thm 7.1 in the Tao-Ziegler paper) where  , but then
, but then 