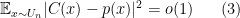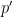Earlier, here and here, we discussed the following problem: we pick at random a k-CNF formula with $n$ variables and $m$ clauses; if $m$ is at least $c_k n$, for a constant $c_k$, then we know that with high probability the formula is unsatisfiable; is there an algorithmic way of certifying this unsatisfiability?
One approach we discussed is a reduction to 2SAT, which works provided $m$ is at least of the order of $n^{k-1}$. What about sparser formulas?
Here is another possible reduction. Starting from the formula, construct an hypergraph that has 2n vertices and m hyperedges as follows. For every variable $x_i$ we have the two vertices $[x_i=0]$ and $[x_i=1]$, and, for every clause with $k$ variables, we have the hyperedge that connects the $k$ vertices corresponding to the unique assignment to those $k$ variables that contradicts the clause. For example, the clause
$(x_3 \vee \neg x_5 \vee x_6)$
corresponds to the hyperedge
$([x_3=0],[x_5=1],[x_6=0])$.
Now, if the formula is random, we have a random hypergraph. Also, if the formula is satisfiable we have an independent set of size $n$; half as big as the total number of vertices: just take the vertices consistent with the assignment. (An independent set is a set of vertices such that no hyperedge is completely contained in the set.) Certifying unsatisfiability of a random formula now reduces to certifying that a given random hypergraph has no large independent set.
Unfortunately, we don’t know of any algorithm for this problem, except for the case of graphs. As I may discuss in a future post, spectral methods allow us to certify that a given random graph with $n$ vertices and average degree $d$ has no independent set larger than about $n/O(\sqrt{d})$. By this, I mean that there is a definition of certificate that, when existing, always correctly proves such an upper bound, and when we pick at random a graph of average degree $d$ there is a high probability that a certificate proving an upper bound of $n/O(sqrt{d})$ to the size of the largest independent set exists and can be found efficiently.
It is too bad that the above reduction produces a graph only when we start from 2SAT, a problem for which we already know how to decide (and hence certify) satisfiability in polynomial time.
But, and here is a great idea of Goerdt and Krivelevich from 2000, we can reduce the problem of certifying non-existence of large independent sets in random hypergraps to the problem of certifying non-existence of large independent sets in random graphs.
Suppose we have an hypergraph with n vertices and m hyperedges, each involving 4 vertices. Construct now a graph with $n^2$ vertices, one for every pairs of vertices in the hypergraph, and for every hyperedge $(a,b,c,d)$ in the hypergraph create the edge $([a,b],[c,d])$ in the graph. (Assume for now that we choose the ordering of vertices at random, even if this means that we only achieve a randomized reduction. There are ways to make the reduction deterministic.) Now, if the hypergraph has an independent set of size $\geq t$ then clearly the graph has an independent set of size $\geq t^2$. Furthermore, if we started from a random hypergraph then we are getting a random graph. So if $m$ is of the order of $n^2$ we are able to refute the claim that there is an independent set of size $n/2$ in the hypergraph (by refuting the claim that there is an independent of size $n^2 /4$ in the graph).
In general, for even $k$, these ideas give a way of refuting a random $k$-SAT instance with $n$ variables and $n^{k/2}$ clauses.
(The original paper of Goerdt and Kirvelevich had an extra polylog term needed to make the spectral techniques work. But later more sophisticated analyses have removed the polylog bound, either by using slightly different reductions or by directly improving the bounds on the sparsity of random graphs for which one can certify the non-existence of large independent sets. See this paper by Feige and Ofek for the latter approach.)
Instead of thinking in terms of reductions to graph and hypergraph problems, one may directly see the method as associating a matrix to the formula and proving that certain properties of the matrix imply the unsatisfiability of the formula.
A generalization of this way of seeing the argument has led to an algorithm by Friedman, Goerdt and Krivelevich that certifies unsatisfiability of random kSAT instances with about $n^{k/2}$ clauses even if $k$ is odd. I think it would be interesting to have a combinatorial view of what happens in that algorithm.
This is the state of the art for algorithms that find certificates of unsatisfiability.
There is also some intuition for why $n^{1.5}$ is a natural barrier. The algorithmic techniques described so far are “no more powerful” than semidefinite programming: the standard semidefinite relaxation of Max 2SAT proves that a given 2SAT formula is unsatisfiable, whenever it is the case, and a standard semidefinite programming relaxation of independent set (the Lovasz theta function) proves with high probability that a random graph has no large independent set. It is conjectured, however, that no “simple” reduction of random 3SAT to a semidefinite programming problem yelds a refutation if the number of clauses is less than $n^{1.5}$. This has been verified by Feige and Ofek for a natural reduction.
Recently, Feige, Kim and Ofek have defined a new type of witness of unsatisfiability that is verifiable in polynomial time and that exists with high probability for formulas with about $n^{1.4}$ clauses. (It is not known, however, how to construct such witnesses in polynomial time given a formula.) As could be expected, their witness-verification algorithm employs something that we know how to do in polynomial time but that is very hard for semidefinite programs: verifying the unsatisfiability of a given linear system over GF(2).








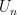



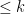

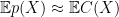



![\displaystyle {\mathbb P}_{x\sim X} [p(x) = C(x) ] = 1-o(1) \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%7B%5Cmathbb+P%7D_%7Bx%5Csim+X%7D+%5Bp%28x%29+%3D+C%28x%29+%5D+%3D+1-o%281%29+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle {\mathbb P}_{x\sim U_n} [p(x) = C(x) ] = 1-o(1) \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%7B%5Cmathbb+P%7D_%7Bx%5Csim+U_n%7D+%5Bp%28x%29+%3D+C%28x%29+%5D+%3D+1-o%281%29+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)