
[In the provincial spirit of Italian newspapers, that often have headlines like “Typhoon in South-East Asia causes widespread destruction; what are the consequences for Italian exports?”, and of men who overhear discussions about women’s issue and say things like “yes, but men have issues too,” I am going to comment on how Babai’s announcement affects me and the kind of problems I work on.]
If someone had told me last week: “a quasi-polynomial time algorithm has been found for a major open problem for which only a slightly subexponential algorithm was known before,” I would have immediately thought Unique Games!
Before Babai’s announcement, Graph Isomorphism had certain interesting properties in common with problems such as Factoring, Discrete Log, and Approximate Closest Vector (for approximation ratios of the order of sqrt (n) or more): no polynomial time algorithm is known, non-trivial algorithms that are much faster than brute force are known, and NP-completeness is not possible because the problem belongs to either 

But there is an important difference: there are simple distributions of inputs on which Factoring, Discrete Log, and Closest Vector approximation are believed to be hard on average, and if one proposes an efficiently implementable algorithms for such problems, it can be immediately shown that it does not work. (Or, if it works, it’s already a breakthrough even without a rigorous analysis.)
In the case of Graph Isomorphism, however, it is easy to come up with simple algorithms for which it is very difficult to find counterexamples, and there are algorithms that are rigorously proved to work on certain distributions of random graphs. Now we know that there are in fact no hard instances at all, but, even before, if we believed that Graph Isomorphism was hard, we had to believe that the hard instances were rare and strange, rather than common.
It is also worth pointing out that, using Levin’s theory of average-case complexity, one can show that if any problem at all in NP is hard under any samplable distribution, then for every NP-complete problem we can find a samplable distribution under which the problem is hard. And, in “practice,” natural NP-complete problems do have simple distributions that seem to generate hard instances.
What about Small-set Expansion, Unique Games, and Unique-Games-Hard problems not known to be NP-hard, like 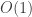
I am sure that it is possible, under standard assumptions, to construct an artificial problem L in NP that is in average-case-P according to Levin’s definition but not in P. Such a problem would not be polynomial time solvable, but it would be easy to solve on average under any samplable distribution and, intuitively, it would be a problem that is hard even though hard instances are rare and strage.
But can a natural problem in NP exhibit this behavior? Now that Graph Isomorphism is not a plausible example any more, I am inclined to believe (until the next surprise) that no natural problem has this behavior, and my guess concerning the Unique Games conjectures is going to be that it is false (or “morally false” in the sense that a quasipolynomial time algorithm exists) until someone comes up with a distribution of Unique Games instances that are plausibly hard on average and that, in particular, exhibit integrality gaps for Lasserre relaxations (even just experimentally).
