The first talk of the morning is by Terry Tao. Tim Gowers, in his essay The Two Cultures of Mathematics explains the difference between depth and generality in combinatorics versus other areas of pure math. In combinatorics, one is unlikely to find deep definitions (have you ever tried to understand the statements of the conjectures in the Langlands program?) and very general theorems. In combinatorics, it is more usual to find generality in the form of principles that the practictioners of the subject are aware of and that are exemplified in the proofs of certain theorems. (I hope I have not distorted and oversimplified Gowers’s point too much.)
Tao’s talk very explicitly points out the principle that emerges from his work on arithmetic progressions. The idea is that one can often define notions of pseudorandomness and structure such that one has a theorem of the following kind:
- Dichotomy: if an object is not pseudorandom, then it has large stuctured component.
For example, in the setting of looking for arithmetic progressions of length 3, a subset of {1,…,N} is “structured” if it has a large Fourier coefficient and it is pseudorandom if it has approximately the same number of length-3 progressions of a random subset of {1,…,N} with the same density.
By iterative arguments, one then has theorems of the form
- Decomposition: every object can be written as a “sum” of a pseudorandom part and a structured part
This is very important in the proof of the Green-Tao theorem on arithmetic progressions in the primes, but it can be seen, implicitly, in the Szemeredi regularity Lemma and in all proofs of Szemeredi’s theorem.
The proof typically goes by: if our object is pseudorandom, we are done; otherwise we find a large structured “piece.” We “subtract” it. If what remains is pseudorandom, we are fine, otherwise we subtract another structured part, and so on.
The advantage of this type of decomposition (whether it is done explicitely or it is implicit in the proof) is that one can use techniques from analysis and probability to analyse the pseudorandom part and (depending on the definition of “structure”) techniques from analysis and geometry to analyse the structured part. This is how the proof of the Green-Tao theorem ends up using analysis, ergodic theory, combinatorics, and so on.
Often, one can use geometry and algebra only provided that the object is “exactly” structured, while results of the above type may only give “approximate” structure. To bridge this gap one employs results of the type:
- Rigidity: an object that is “approximately structured” is “close” to an object that is structured
These are results in the spirit of property testing. (And he mentions property testing in his talk.)
This is all quite abstract, but reading papers in the area (or approaching new problems) with this point of view in mind is very helpful. He also proceeds to summarize the proof of the Green-Tao theorem in terms of the above perspective.
By the way, earlier in the talk, about the general importance of understanding pseudorandomness, Tao talks mentions expander graphs and the P versus BPP question. (As a context, not as specific problems that he is going to work on. For the time being, we are safe.)
Overall, the talk is a model of clarity and insight.
After the break, Avi Wigderson gives his talk on P, NP and Mathematics. Yesterday, Avi told me that, of all the material that he cover in his 50-page proceedings paper, he had decided to talk about pseudorandomness and derandomization, from the perspective that randomness seems to help in computation, but complexity theory suggests that it does not. I despaired, because this is exactly my talk, but luckily Avi’s talk has a somewhate complementary emphasis on topics. (So I won’t have to spend the next two days remaking my slides and I can go see the Prado tomorrow.)
Avi explains the “hardness versus randomness” principle in terms that could not be clearer, and one can see heads nodding as he goes along (nodding in agreement, not nodding off). He ends up with the following question about the complexity of the permanent: is there a linear transformation L of nXn matrices into kXk matrices such that, (i) for every matrix M, the determinant of L(M) equals the permanent of M and (ii) k is only polynomial in n? (The answer is supposed to be NO.) From known results one can derive that k need not be more than exp(O(n)) and a Omega(n2) lower bound is also known.
This is to say that one can work on complexity theory without having to learn about such things as algorithms, Turing machines and so on, and that purely algebraic questions are completely open and very related to complexity questions.


 and then, at any time, be able to prove that
and then, at any time, be able to prove that  and the prover knows a 3-coloring. A physical analog of the protocol (which can be implemented using the notion of commitment schemes) is the following: the prover randomizes the color labels, then takes
and the prover knows a 3-coloring. A physical analog of the protocol (which can be implemented using the notion of commitment schemes) is the following: the prover randomizes the color labels, then takes 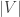 lockboxes, each labeled by a vertex, and puts a piece of paper with the color of vertex
lockboxes, each labeled by a vertex, and puts a piece of paper with the color of vertex  in the lockbox labeled by
in the lockbox labeled by 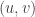 and asks for the keys of the lockboxes for
and asks for the keys of the lockboxes for  and for
and for  of picking such an edge and rejecting. Thus the verifier accepts with probability at most
of picking such an edge and rejecting. Thus the verifier accepts with probability at most  , which can be made negligibly small by repeating the protocol several times.
, which can be made negligibly small by repeating the protocol several times. unopened lockboxes. A view with such a distribution can be easily sampled, and the same is true when the physical implementation is replaced by a commitment scheme. (Technically, this is argument only establishes honest-verifier zero knowledge, and a bit more work is needed to capture a more general property.)
unopened lockboxes. A view with such a distribution can be easily sampled, and the same is true when the physical implementation is replaced by a commitment scheme. (Technically, this is argument only establishes honest-verifier zero knowledge, and a bit more work is needed to capture a more general property.)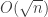 colors? Here is the algorithm, which has the flavor of Ramsey theory proofs.
colors? Here is the algorithm, which has the flavor of Ramsey theory proofs. 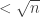 , then we can easily color the graph with
, then we can easily color the graph with 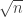 colors. Otherwise, there is a node
colors. Otherwise, there is a node 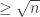 . The neighbors of
. The neighbors of 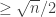 . So we keep finding independent sets (which we assign a color to, and remove) of size
. So we keep finding independent sets (which we assign a color to, and remove) of size  until we get to a point where we know how to color the residual graph with
until we get to a point where we know how to color the residual graph with  colors, meaning that we can color the whole graph with
colors, meaning that we can color the whole graph with  colors.
colors.