
Edited 5/7/2018. Thanks to Sam Hopkins for several corrections and suggestions.
I am revising my notes from the course on “better-than-worst-case” analysis of algorithms. With the benefit of hindsight, in this post (and continuing in future posts) I would like to review again how one applies spectral methods and semidefinite programming to problems that involve a “planted” solution, and what is the role of concentration results for random matrices in the analysis of such algorithms.
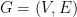 with an unknown partition of the vertices into two equal parts
with an unknown partition of the vertices into two equal parts 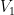 and
and  . Edges across the partition are generated independently with probability
. Edges across the partition are generated independently with probability  , and edges inside the partition are generated independently with probability
, and edges inside the partition are generated independently with probability  . To abbreviate the notation, we let
. To abbreviate the notation, we let  , which is the average internal degree, and
, which is the average internal degree, and  , which is the average external degree. Intuitively, the closer are
, which is the average external degree. Intuitively, the closer are  and
and  , the more difficult it is to reconstruct the partition. We assume
, the more difficult it is to reconstruct the partition. We assume 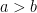 , although there are also similar results in the complementary model where
, although there are also similar results in the complementary model where  so that the graph is not almost empty.
so that the graph is not almost empty.
 , there exists a constant
, there exists a constant 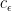 such that if
such that if 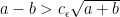 , then we can reconstruct the partition up to less than
, then we can reconstruct the partition up to less than  misclassified vertices.
misclassified vertices.  such that if
such that if  , then we can do exact reconstruct.
, then we can do exact reconstruct.
 such that if
such that if  , then it will be impossible to reconstruct the partition even if an
, then it will be impossible to reconstruct the partition even if an  fraction of misclassified vertices is allowed. Also, the constant
fraction of misclassified vertices is allowed. Also, the constant  needs to be a bigger and bigger constant times
needs to be a bigger and bigger constant times  . When the constant becomes
. When the constant becomes  , we will get an exact reconstruction as stated in the second result.
, we will get an exact reconstruction as stated in the second result.
 problem
problem  vertices where
vertices where  is partitioned into two 2 subsets of equal size:
is partitioned into two 2 subsets of equal size:  . Then for
. Then for 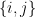 pair of vertices in the same subset,
pair of vertices in the same subset,  and otherwise
and otherwise  .
. 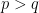 . If we want to find the partition
. If we want to find the partition 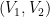 has expected size
has expected size  and any other cut will have greater expected size.
and any other cut will have greater expected size.
 , the problem only gets harder. And for fixed ratio
, the problem only gets harder. And for fixed ratio  , as
, as 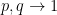 , the problem only gets easier. This can be stated rigorously as follows: If we can solve the problem for
, the problem only gets easier. This can be stated rigorously as follows: If we can solve the problem for 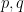 then we can also solve it for
then we can also solve it for  where
where 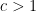 , by keeping only
, by keeping only  edges and reducing to the case we can solve.
edges and reducing to the case we can solve.
 -planted clique problem, we found the eigenvector
-planted clique problem, we found the eigenvector  corresponding to the largest eigenvalue of
corresponding to the largest eigenvalue of  . We then defined
. We then defined  as the vertices
as the vertices  with the
with the 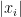 and cleaned up
and cleaned up  . Note this is intuitive as the average degree of the graph is
. Note this is intuitive as the average degree of the graph is  . The idea is simple: Solve
. The idea is simple: Solve 
