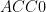If we pick at random a function f:{0,1}n->{0,1}, then, very likely, f has circuit complexity at least about 2n/n. Can we derandomize this application of the probabilistic method, and construct such a function in time polynomial in the length of its representation, 2n? This is, of course, the question of whether we can prove exponential circuit lower bounds in E (the complexity class of problems solvable in time 2O(n)).
Consider now the following problems. (1) Given a multivariate polynomial p of degree d (specified as an algebraic circuit) defined over a field F of size > 2d, and assuming that p is not always zero, find an input on which p is not zero. We know that p is non-zero on at least half of the inputs, but is there an efficient deterministic algorithm for this problem? (2) With high probability, a random graph on n vertices has no clique and no independent set of size more than 2log n. Can we deterministically construct such a graph? (3) With high probability, a random d-regular graph on n vertices has very good expansion. Can we deterministically construct such graphs? (4) If we pick a random n x (rho * n) matrix over a finite field, it defines with high probability a linear error-correcting code with rate rho and with good minimum distance. Can we deterministically construct such codes?
There is a superficial similarity to all these problems. We are interested in combinatorial objects with a certain property, we know that a random object has the property with high probability, and we want to deterministically construct an object with the property. (In time polynomial in its size.)
One important distinction is whether or not the property that we are interested (or some good “approximation”) is efficiently computable. For example, in the case of the polynomial identity testing problem, we know when an input makes a polynomial non-zero, and, regarding expanders, computing the eigenvalue gap of a given regular graph gives an approximation of its expansion.
If very strong pseudorandom generators (or even “hitting set” generators) exist, then one can solve these explicit construction problems simply by looking at all the possible outputs of the generators. One of them must satisfy the property. This is the argument that proves that all probabilistic algorithms (including, for example, polynomial identity testing) can be derandomized if very strong generators exist.
It would require major algorithmic breakthroughs, however, to certify strong upper bounds to the independence number of a random graph (I think that currently the best upper bound is sqrt(n), via spectral methods), or to certify that a random matrix defines a good linear code, or to certify that a random graph has expansion beyond the eigenvalue bound. It is unclear how to use a generator to solve these explicit construction problems. (Under suitable assumptions, we would still be guaranteed that one possible output of the generator has the property, but we would not know which one.)
What about checking whether a given function f:{0,1}n->{0,1} (think of it as a binary string of length N=2n) has high circuit complexity?
Razborov and Rudich prove the remarkable result that if suitably strong one-way functions (and, hence, pseudorandom generators) exist, then there is a distribution of functions f:{0,1}n->{0,1} (again, think of them as binary strings of length N=2n) concentrated on functions of circuit complexity at most nlog n, that is indistinguishable from the uniform distribution over all boolean functions f:{0,1}n->{0,1} for algorithms of running time poly(N) = 2O(n). This means that (assuming the existence of the appropriate one-way functions), the problem “given the truth table of a boolean function, compute its circuit complexity” is intractable and, in fact, even hard to approximate. Even more remarkably, the problem is hard-on-average, even just to approximate. It is perhaps the only natural problem that is known to be hard-on-average under standard assumptions.
To come back to our discussion, if strong pseudorandom generators exists, we cannot “derandomize” the problem of constructing a function of high circuit complexity by simply using a strong pseudorandom generator and then picking one
of the outputs. There is, however, a way to show that the existence of strong pseudorandom generators does indeed imply the ability to construct functions of high circuit complexity. Here the circularity may make you feel a bit dizzy, so let’s move on to the reason why Razborov and Rudich proved their remarkable result.
Their observation was that in all the circuit lower bound arguments known at the time (for example, in the proof that parity has no AC0 circuit) one can recognize a certain pattern: one defines a property of functions which implies the circuit lower bound (in the case of the AC0 lower bound, the property of remaining non-constant after a large number of variables have been randomly fixed) and then proves that a specific function satisfies the property. Razborov and Rudich call such an argument a “natural proof” if (i) the property is computable in time 2O(n) and (ii) the property is true with noticeable probability for a random function. Their result rules out super-polynomial circuit lower bounds proved via a natural proof (assuming strong enough one-way functions). This is because the property used in the natural proof would be an efficiently computable distinguisher between the Razborov-Rudich distribution (which is made of functions of low circuit complexity, and so satisfies the property with probability zero) and the uniform distribution over functions (which is assumed to satify the property with noticeable probability).
More than ten years later, the only candidate technique for non-natural lower bounds is a combination of diagonalization (which tends to lead to non-natural arguments) and of non-relativizing characterizations of complexity classes (because diagonalization alone cannot prove non-relativizing results, and EXP has polynomial size circuits relative to an oracle). In particular, these are the ingredients used by Buhrman et al. in proving that there are problems in MAEXP and PEXP of superpolynomial circuit complexity, and by Vinodchandran to prove that, for every fixed k, PP has problems of circuit complexity more than nk.
It should be noted that we do know explicit constructions of expanders, Ramsey graphs and error-correcting codes whose properties are stronger than the properties that we know how to certify for random graphs and random matrices. Even though the analogy may be faulty, I think we should remain optimistic that we will eventually find a way to explicitly construct functions of high circuit complexity in EXP.