
In a previous post, I described abstract forms of the weak regularity lemma, in which we start from an arbitrary bounded function ![g: X \rightarrow [-1,1]](https://s0.wp.com/latex.php?latex=g%3A+X+%5Crightarrow+%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)

![f: X \rightarrow [-1,1]](https://s0.wp.com/latex.php?latex=f%3A+X+%5Crightarrow+%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)





In a new paper by Madhur Tulsiani, Salil Vadhan, and I, we give a new proof that gives an approximating function that, at the same time, is bounded and has low complexity. This has a number of applications, which I will describe in a future post.
(Note that, in the statement below, 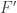
![\{ 1_{f(x) \geq t} \ : \ f\in F, t\in [-1,1] \}](https://s0.wp.com/latex.php?latex=%5C%7B+1_%7Bf%28x%29+%5Cgeq+t%7D+%5C+%3A+%5C+f%5Cin+F%2C+t%5Cin+%5B-1%2C1%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Theorem (Low Complexity Approximation, TTV Version) Let 
![g:X \rightarrow [-1,1]](https://s0.wp.com/latex.php?latex=g%3AX+%5Crightarrow+%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)

Then there is a function ![h: X \rightarrow [-1,1]](https://s0.wp.com/latex.php?latex=h%3A+X+%5Crightarrow+%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002)
-
functions
and coefficients
such that
-
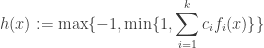

That is, 

Recall that, when we do not require
Algorithm FK
0;
- while
such that
-
- return



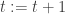
And the analysis shows that, if we call 

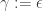

Our proof proceeds by doing exactly the same, but making sure at every step that
Algorithm TTV
- while
-
- return

The problem with the old analysis is that now we could conceivably have a step in which 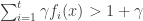

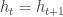
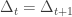
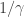


Unfortunately I don’t know how to construct such a proof. Our proof, instead, follows step by step Impagliazzo’s proof of the Impagliazzo Hardcore Set Lemma, which employs a very similar algorithm (in a quite different context). As shown by Klivans and Servedio, the algorithm in Impagliazzo’s proof can be seen as a boosting algorithm in learning theory (and every other known boosting algorithm can be used to prove Impagliazzo’s Hardcore Lemma); this is why we think of our proof as a “boosting” proof.
I must confess, I have never really understood Impagliazzo’s proof, and so I can’t say I really understand ours, other than being able to reproduce the steps.
The idea is to consider the quantity 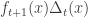

Suppose the algorithm is still running after


and the crux of the proof is to show that for every

So if we sum (1) over
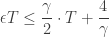
and setting 
Inequality (2), the main step of the proof, is the part for which I have little intuition. One breaks the summation into groups of time steps, depending on the value of 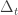

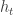

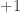

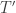
It is perhaps instructive to translate the Frieze-Kannan proof to this set-up. In the Frieze-Kannan algorithm, we have
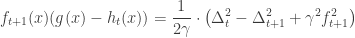
and so
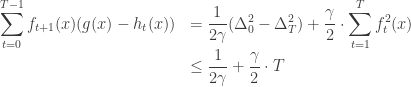
which is analogous to our inequality (2).

Pingback: Applications of Low-Complexity Approximations « in theory