
Welcome to phase two of in theory, in which we again talk about math. I spent last Fall teaching two courses and getting settled, I mostly traveled in January and February, and I have spent the last two months on my sofa catching up on TV series. Hence I will reach back to last Spring, when I learned about Talagrand’s machinery of generic chaining and majorizing measures from Nikhil Bansal, in the context of our work with Ola Svensson on graph and hypergraph sparsification. Here I would like to record what I understood about the machinery, and in a follow-up post I plan to explain the application to hypergraph sparsification.
1. A Concrete Setting
Starting from a very concrete setting, suppose that we have a subset 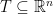

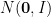

In theoretical computer science, for example, a random variable like (1) comes up often in the study of rounding algorithms for semidefinite programming, but this is a problem of much broader interest.
We will be interested both in bounds on the expectations of (1) and on its tail, but in this post we will mostly reason about its expectation.
A first observation is that each 



![\displaystyle \Pr \left[ \sup_{t\in T}\ \langle g, t \rangle > \ell \right] \leq |T| \cdot e^{-\ell^2 / 2 \sup_{t\in T} ||t||^2}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CPr+%5Cleft%5B+%5Csup_%7Bt%5Cin+T%7D%5C+%5Clangle+g%2C+t+%5Crangle+%3E+%5Cell+%5Cright%5D+%5Cleq+%7CT%7C+%5Ccdot+e%5E%7B-%5Cell%5E2+%2F+2+%5Csup_%7Bt%5Cin+T%7D+%7C%7Ct%7C%7C%5E2%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
and we can compute the upper bound
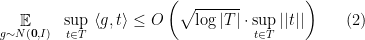
The above bound can be tight, but it is poor if the points of
It is useful to note that, if we fix, arbitrarily, an element 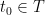

because 
In the cases in which (2) gives a poor bound, a natural approach is to reason about an 

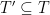
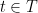

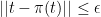




which can be a much tighter bound. Notice that we used (2) to bound

but it might actually be better to find an 

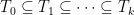
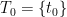

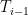
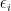


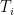
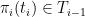

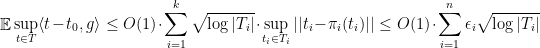
Finally, if the cardinality of the 
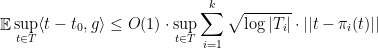
where 

At this point, we do not even need to assume that 
Theorem 1 (Talagrand’s generic chaining inequality) Let
be a countable sequence of finite subsets of
and
. Then
where
is the element of
closest to
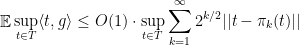
A short complete proof is in these notes by James Lee.
While the above Theorem has a very simple proof, the amazing thing, which is rather harder to prove, is that it is tight, in the sense that for every 

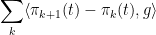
of projections of the intermediate steps of a path that goes from 
2. An Abstract Setting
Let now 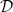


That is, we have a random optimization problem with a fixed feasible set 



We will call the collection of random variables 

If every 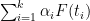

If 

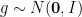
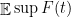
If 
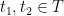
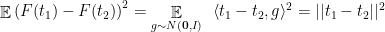
and, by analogy, if

If
We will not need this fact, but if 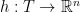




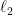
The arguments of the previous section apply to centered Gaussian processes without change, and so we have.
Theorem 2 Let
where
is the distance function
and
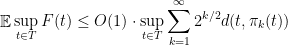
3. Sub-Gaussian Random Processes
This theory does not seem to apply to problems such as bounding the max cut of a 

Fortunately, there is a notion of a sub-Gaussian process, which applies to such problems and which reduces their analysis to the analysis of a related Gaussian process.
First, recall that a centered real-valued random variable 


![\displaystyle \Pr [ X \geq t ] \leq k \cdot e^{-t^2 /v }](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CPr+%5B+X+%5Cgeq+t+%5D+%5Cleq+k+%5Ccdot+e%5E%7B-t%5E2+%2Fv+%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
An equivalent condition is that there is a

In that case, we can define a norm, called the 

which is, roughly, the standard deviation of a centered Gaussian that dominates
Example 1 All bounded random variables are sub-Gaussian.
Example 2 If
where the
are independent Rademacher random variables, that is, if each
, which is within a constant factor of its actual standard deviation.

Example 3 If
where the
of being equal to
and probability
(that is, each
, which is much more than the standard deviation of
Example 4 If
where the
are arbitrary real scalars, then
, which is within a constant factor of the standard deviation that we would get by replacing each

Let now 


That is, every random variable of the form 

Theorem 3 (Talagrand’s comparison inequality) There is an absolute constant
such that if
Furthermore, for every
,
where
is the diameter of
.
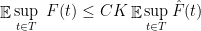
![\displaystyle \Pr \left[ \sup_{t_1,t_2 \in T} F(t_1) - F(t_2) \geq CK \ \left( \ell \cdot diam(T) + \mathop{\mathbb E} \sup_{t\in T} \hat F(t) \right) \right] \leq 2 e^{-\ell^2} \ ,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5CPr+%5Cleft%5B+%5Csup_%7Bt_1%2Ct_2+%5Cin+T%7D+F%28t_1%29+-+F%28t_2%29+%5Cgeq+CK+%5C+%5Cleft%28+%5Cell+%5Ccdot+diam%28T%29+%2B+%5Cmathop%7B%5Cmathbb+E%7D+%5Csup_%7Bt%5Cin+T%7D+%5Chat+F%28t%29+%5Cright%29+%5Cright%5D+%5Cleq+2+e%5E%7B-%5Cell%5E2%7D+%5C+%2C+&bg=ffffff&fg=000000&s=0&c=20201002)
The way to apply this theory is the following.
Suppose that we want estimate, on average or with high probability, the optimum of an optimization problem with feasible set
Then we think about a related random experiment, in which the random choices involved in constructing our instance are replaced by Gaussian choices (for example, instead of a 

If we can argue that 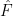

4. An Example
We will now use this machinery to show that the largest eigenvalue of a random symmetric 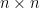
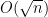
We let 
Our Gaussian process will be to pick standard Gaussians 
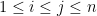
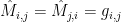

for every 
Our “sub-Gaussian” random process is to pick Rademacher random variables 


for every
We will argue that 
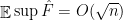
For the first claim, we see that for every 


So, as noted in one of our examples above, we can say that

and we see that

so that, indeed,
Now we need to apply generic chaining to 


where we used the inequality

We can conclude that an 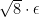
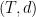

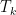

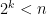



Very nice!
Nice post! I think there is a missing parenthesis in the displayed equation defining d(t1,t2).
The equation for the definition of the Psi2 norm does not show correctly.
Thanks for the corrections
Pingback: To cheer you up in difficult times 3: A guest post by Noam Lifshitz on the new hypercontractivity inequality of Peter Keevash, Noam Lifshitz, Eoin Long and Dor Minzer | Combinatorics and more
Pingback: Spielman-Srivastava Sparsification à la Talagrand | in theory
I was wondering, how do you obtain the bound for (2) when T is finite? I guess you integrate P(X > l) but I was wondering if there was a trick to get that bound?
Pingback: An upper bound on Gaussian mean width – Mathematics – Forum