Last revised 4/29/2010
In this lecture we define 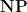 , we state the
, we state the 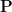 versus problem, we prove that its formulation for search problems is equivalent to its formulation for decision problems, and we prove the time hierarchy theorem, which remains essentially the only known theorem which allows to show that certain problems are not in .
versus problem, we prove that its formulation for search problems is equivalent to its formulation for decision problems, and we prove the time hierarchy theorem, which remains essentially the only known theorem which allows to show that certain problems are not in .
1. Computational Problems
In a computational problem, we are given an input that, without loss of generality, we assume to be encoded over the alphabet 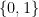 , and we want to return as output a solution satisfying some property: a computational problem is then described by the property that the output has to satisfy given the input.
, and we want to return as output a solution satisfying some property: a computational problem is then described by the property that the output has to satisfy given the input.
In this course we will deal with four types of computational problems: decision problems, search problems, optimization problems, and counting problems.\footnote{ This distinction is useful and natural, but it is also arbitrary: in fact every problem can be seen as a search problem} For the moment, we will discuss decision and search problem.
In a decision problem, given an input 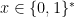 , we are required to give a YES/NO answer. That is, in a decision problem we are only asked to verify whether the input satisfies a certain property. An example of decision problem is the 3-coloring problem: given an undirected graph, determine whether there is a way to assign a “color” chosen from
, we are required to give a YES/NO answer. That is, in a decision problem we are only asked to verify whether the input satisfies a certain property. An example of decision problem is the 3-coloring problem: given an undirected graph, determine whether there is a way to assign a “color” chosen from 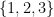 to each vertex in such a way that no two adjacent vertices have the same color.
to each vertex in such a way that no two adjacent vertices have the same color.
A convenient way to specify a decision problem is to give the set 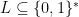 of inputs for which the answer is YES. A subset of
of inputs for which the answer is YES. A subset of 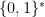 is also called a language, so, with the previous convention, every decision problem can be specified using a language (and every language specifies a decision problem). For example, if we call 3COL the subset of containing (descriptions of) 3-colorable graphs, then 3COL is the language that specifies the 3-coloring problem. From now on, we will talk about decision problems and languages interchangeably.
is also called a language, so, with the previous convention, every decision problem can be specified using a language (and every language specifies a decision problem). For example, if we call 3COL the subset of containing (descriptions of) 3-colorable graphs, then 3COL is the language that specifies the 3-coloring problem. From now on, we will talk about decision problems and languages interchangeably.
In a search problem, given an input  we want to compute some answer
we want to compute some answer 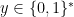 that is in some relation to
that is in some relation to  , if such a
, if such a  exists. Thus, a search problem is specified by a relation
exists. Thus, a search problem is specified by a relation  , where
, where  if and only if is an admissible answer given .
if and only if is an admissible answer given .
Consider for example the search version of the 3-coloring problem: here given an undirected graph 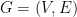 we want to find, if it exists, a coloring
we want to find, if it exists, a coloring  of the vertices, such that for every
of the vertices, such that for every 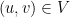 we have
we have  . This is different (and more demanding) than the decision version, because beyond being asked to determine whether such a
. This is different (and more demanding) than the decision version, because beyond being asked to determine whether such a  exists, we are also asked to construct it, if it exists. Formally, the 3-coloring problem is specified by the relation
exists, we are also asked to construct it, if it exists. Formally, the 3-coloring problem is specified by the relation  that contains all the pairs
that contains all the pairs  where
where  is a 3-colorable graph and is a valid 3-coloring of .
is a 3-colorable graph and is a valid 3-coloring of .
2. P and NP
In most of this course, we will study the asymptotic complexity of problems. Instead of considering, say, the time required to solve 3-coloring on graphs with 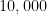 nodes on some particular model of computation, we will ask what is the best asymptotic running time of an algorithm that solves 3-coloring on all instances. In fact, we will be much less ambitious, and we will just ask whether there is a “feasible” asymptotic algorithm for 3-coloring. Here feasible refers more to the rate of growth than to the running time of specific instances of reasonable size.
nodes on some particular model of computation, we will ask what is the best asymptotic running time of an algorithm that solves 3-coloring on all instances. In fact, we will be much less ambitious, and we will just ask whether there is a “feasible” asymptotic algorithm for 3-coloring. Here feasible refers more to the rate of growth than to the running time of specific instances of reasonable size.
A standard convention is to call an algorithm “feasible” if it runs in polynomial time, i.e. if there is some polynomial  such that the algorithm runs in time at most
such that the algorithm runs in time at most  on inputs of length
on inputs of length  .
.
We denote by the class of decision problems that are solvable in polynomial time.
We say that a search problem defined by a relation  is a search problem if the relation is efficiently computable and such that solutions, if they exist, are short. Formally, is an search problem if there is a polynomial time algorithm that, given and , decides whether
is a search problem if the relation is efficiently computable and such that solutions, if they exist, are short. Formally, is an search problem if there is a polynomial time algorithm that, given and , decides whether 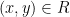 , and if there is a polynomial such that if then
, and if there is a polynomial such that if then  .
.
We say that a decision problem  is an decision problem if there is some relation such that
is an decision problem if there is some relation such that 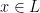 if and only if there is a such that . Equivalently, a decision problem is an decision problem if there is a polynomial time algorithm
if and only if there is a such that . Equivalently, a decision problem is an decision problem if there is a polynomial time algorithm 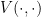 and a polynomial such that if and only if there is a , such that
and a polynomial such that if and only if there is a , such that  accepts.
accepts.
We denote by the class of decision problems. The class has the following alternative characterization, from which it takes its name. ( stands for Nondeterministic Polynomial time.)
Theorem 1 is the set of decision problems that are solvable in polynomial time by a non-deterministic Turing machine.
Proof: Suppose that is solvable in polynomial time by a non-deterministic Turing machine  : then we can define the relation such that
: then we can define the relation such that  if and only if
if and only if  is a transcript of an accepting computation of on input (that is, the sequence of configurations of an accepting branch of on input ) and it’s easy to prove that is an relation and that is in according to our first definition. Suppose that is in according to our first definition and that is the corresponding relation. Then, on input , a non-deterministic Turing machine can guess a string of length less than
is a transcript of an accepting computation of on input (that is, the sequence of configurations of an accepting branch of on input ) and it’s easy to prove that is an relation and that is in according to our first definition. Suppose that is in according to our first definition and that is the corresponding relation. Then, on input , a non-deterministic Turing machine can guess a string of length less than  and then accept if and only if . Such a machine can be implemented to run in non-deterministic polynomial time and it decides .
and then accept if and only if . Such a machine can be implemented to run in non-deterministic polynomial time and it decides . 
The reason why , as a complexity class, is defined as a class of decision problems rather than search problems is that one can develop a cleaner theory for decision problems (the definition of reduction, for example, is simpler), and the complexity of decision problems in completely characterizes the complexity of search problems.
Theorem 2 For every search problem there is an decision problem such that if the decision problem is solvable in time 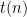 then the search problem is solvable in time
then the search problem is solvable in time 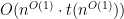 . In particular,
. In particular,  if and only if every search problem is solvable in polynomial time.
if and only if every search problem is solvable in polynomial time.
Proof: Let be an relation defining an search problem. Then consider the following decision problem:
- Input: a pair of strings

- Goal: determine if there is a string
 such that
such that  , where
, where  denotes string concatenation.
denotes string concatenation.
Suppose the above decision problem is solvable in time  by an algorithm
by an algorithm  . Then consider the following algorithm for the search problem (
. Then consider the following algorithm for the search problem ( denotes the empty string):
denotes the empty string):
- Input
- if
 , then return “no solution”
, then return “no solution”
-

- while

- return

If there is no solution for , then the algorithm discovers that at the beginning. Otherwise, every iteration of the while loop increases the length of while maintaining the invariant that is a prefix of a valid solution to . Since is an relation, such a solution must be of length polynomial in the length of , and so the loop terminates after a polynomial number of iterations, with a valid solution.
For a function 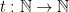 , we define by
, we define by  the set of decision problems that are solvable by a deterministic Turing machine within time on inputs of length , and by
the set of decision problems that are solvable by a deterministic Turing machine within time on inputs of length , and by  the set of decision problems that are solvable by a non-deterministic Turing machine within time on inputs of length . Hence,
the set of decision problems that are solvable by a non-deterministic Turing machine within time on inputs of length . Hence,  and
and 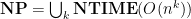 .
.
3. Diagonalization
Diagonalization is essentially the only way we know of proving separations between complexity classes. The basic principle is the same as in Cantor’s proof that the set of real numbers is not countable. First note that if the set of real numbers  in the range
in the range 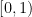 is countable then the set of infinite binary sequences is countable: we can identify a real number in with its binary expansion
is countable then the set of infinite binary sequences is countable: we can identify a real number in with its binary expansion ![{r = \sum_{j=1}^{\infty} 2^{-j} r[j]}](https://s0.wp.com/latex.php?latex=%7Br+%3D+%5Csum_%7Bj%3D1%7D%5E%7B%5Cinfty%7D+2%5E%7B-j%7D+r%5Bj%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . If we had an enumeration of real numbers, then we would also have an enumeration of infinite binary string. (The only thing to watch for is that some real numbers may have two possible binary representations, like
. If we had an enumeration of real numbers, then we would also have an enumeration of infinite binary string. (The only thing to watch for is that some real numbers may have two possible binary representations, like  and
and 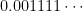 .)
.)
So, suppose towards a contradiction that the set of infinite binary sequences were countable, and let ![{B_i[j]}](https://s0.wp.com/latex.php?latex=%7BB_i%5Bj%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) be the
be the  -th bit of the
-th bit of the  -th infinite binary sequence. Then define the sequence
-th infinite binary sequence. Then define the sequence  whose -th bits is
whose -th bits is ![{1-B_j[j]}](https://s0.wp.com/latex.php?latex=%7B1-B_j%5Bj%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . This is a well-defined sequence but there can be no such that
. This is a well-defined sequence but there can be no such that  , because differs from
, because differs from  in the -th bit.
in the -th bit.
Similarly, we can prove that the Halting problem is undecidable by considering the following decision problem  : on input
: on input  , the description of a Turing machine, answer NO if
, the description of a Turing machine, answer NO if  halts and accepts and YES otherwise. The above problem is decidable if the Halting problem is decidable. However, suppose where decidable and let
halts and accepts and YES otherwise. The above problem is decidable if the Halting problem is decidable. However, suppose where decidable and let  be a Turing machine that solves , then
be a Turing machine that solves , then  halts and accepts if and only if does not halt and accept, which is a contradiction.
halts and accepts if and only if does not halt and accept, which is a contradiction.
It is easy to do something similar with time-bounded computations.
Definition 3 (Time constructible functions) A function  is time constructible if there is an algorithm that, on input , computes the value in time
is time constructible if there is an algorithm that, on input , computes the value in time 
All polynomials are time constructible, as well as all combinations of exponential, polynomial, and root functions such as  ,
,  ,
, 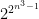 , and so on. Indeed, one needs to work quite hard to come with an example of a function that is not time constructible. One example of a function that is not time constructible is the following: define to equal
, and so on. Indeed, one needs to work quite hard to come with an example of a function that is not time constructible. One example of a function that is not time constructible is the following: define to equal 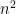 if the number written in binary encodes a turing machine that halts on all inputs, and define to equal
if the number written in binary encodes a turing machine that halts on all inputs, and define to equal 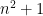 otherwise.
otherwise.
Theorem 4 (Time hierarchy theorem — simplified version) For every time-constructible function 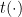 , there is a language such that every algorithm that decides must run in time
, there is a language such that every algorithm that decides must run in time 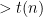 on infinitely many inputs, but
on infinitely many inputs, but  .
.
Proof: The theorem holds for any model of computation which is simulable within the model. For concreteness, we give the proof for the case of Turing machine. We define the language

That is, an input to the problem is a pair  , where is a Turing machine and is a possible input for , and the goal of the problem is to determine whether , on input , halts and rejects in at most steps, where is the length of .
, where is a Turing machine and is a possible input for , and the goal of the problem is to determine whether , on input , halts and rejects in at most steps, where is the length of .
First, we note that is decidable in time polynomial in on inputs of length . Given an input , we compute , where is the length of in time (here we are using the time-constructibility of ) and then we run a simulation of the computation of on input . If the simulation halts and reject within steps, then we accept. If the simulation accepts within steps, or is still running after 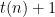 steps, then we reject.
steps, then we reject.
It remains to argue that every machine that decides must run in time 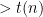 for infinitely many inputs.
for infinitely many inputs.
Let  be a machine that decides and let be any string. Suppose that , on input
be a machine that decides and let be any string. Suppose that , on input  , halts after
, halts after  steps. Then if , on input , rejects, then
steps. Then if , on input , rejects, then  , by definition of , and so is incorrectly deciding on input . If , on input accepts, then
, by definition of , and so is incorrectly deciding on input . If , on input accepts, then  , and so is again incorrect. In either case we reach a contradiction to the assumption that decides .
, and so is again incorrect. In either case we reach a contradiction to the assumption that decides .
It follows that halts after 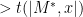 steps on all the inputs of the form , of which there are infinitely many.
steps on all the inputs of the form , of which there are infinitely many.
We define two more complexity classes in order to derive certain simple consequences of the time hierarchy theorem.
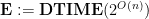

Corollary 5  and
and 
Proof: Apply the time hierarchy theorem to  , and let be the resulting language. Then is decidable in time
, and let be the resulting language. Then is decidable in time  , and so it is in
, and so it is in 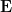 . Suppose that
. Suppose that  , and so that there is a machine that decides in time at most on inputs of length , where
, and so that there is a machine that decides in time at most on inputs of length , where  is a polynomial. Since
is a polynomial. Since  for all but finitely many values of , contradicting the property of guaranteed by the time hierarchy theorem.
for all but finitely many values of , contradicting the property of guaranteed by the time hierarchy theorem.
Apply the time hierarchy theorem to  , and let
, and let  be the resulting language. Then is decidable in time
be the resulting language. Then is decidable in time  , and so
, and so  , but we cannot have
, but we cannot have  or else the machine deciding in time would run in time
or else the machine deciding in time would run in time 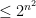 for all but a finite number of inputs.
for all but a finite number of inputs.

then


Thank you for posting this.
I think there is a typo in Theorem 2 – “if the decision problem is solvable in time {t(n)} then the decision problem is solvable in time {O(n^{O(1)} \cdot t(n))}”.
Thanks for a great post.
There is an unfinished sentence just before theorem 4:
“Indeed, one needs to work quite hard to”
Great post.
To be compatible with the algorithm for the search problem, shouldn’t the decision problem in the proof of theorem 2 decide if there’s a suffix z such that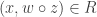 ?
?