In this lecture we introduce the computational model of boolean circuits and prove that polynomial size circuits can simulate all polynomial time computations. We also begin to talk about randomized algorithms.
1. Circuits
A circuit  has
has  inputs,
inputs,  outputs, and is constructed with AND gates, OR gates and NOT gates. Each gate has in-degree 2 except the NOT gate which has in-degree 1. The out-degree can be any number. A circuit must have no cycle. The following picture shows an example of a boolean circuit computing the function
outputs, and is constructed with AND gates, OR gates and NOT gates. Each gate has in-degree 2 except the NOT gate which has in-degree 1. The out-degree can be any number. A circuit must have no cycle. The following picture shows an example of a boolean circuit computing the function 
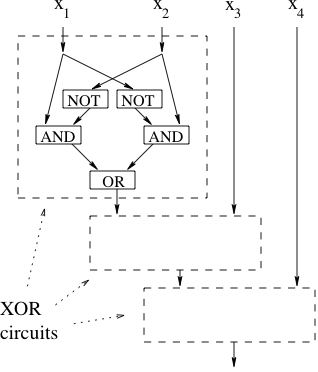
Define  of AND and OR gates of . By convention, we do not count the NOT gates.
of AND and OR gates of . By convention, we do not count the NOT gates.
To be compatible with other complexity classes, we need to extend the model to arbitrary input sizes:
Definition 1 A language  is solved by a family of circuits
is solved by a family of circuits 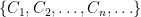 if for every
if for every  and for every
and for every  s.t.
s.t. 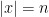 ,
,

Definition 2 Say  if is solved by a family of circuits, where
if is solved by a family of circuits, where  has at most
has at most  gates.
gates.
2. Relation to other complexity classes
Unlike other complexity measures, like time and space, for which there are languages of arbitrarily high complexity, the size complexity of a problem is always at most exponential.
Theorem 3 For every language ,  .
.
Proof: We need to show that for every 1-output function 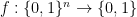 ,
,  has circuit size
has circuit size  .
.
Use the identity  to recursively construct a circuit for , as shown in the figure below
to recursively construct a circuit for , as shown in the figure below
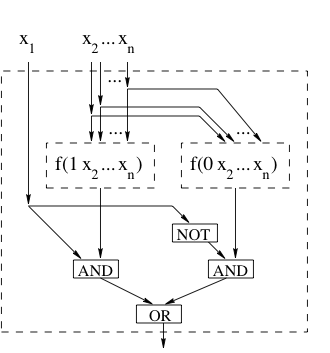
The recurrence relation for the size of the circuit is:  with base case
with base case 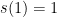 , which solves to
, which solves to  .
. 
The exponential bound is nearly tight.
Theorem 4 There are languages such that 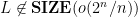 . In particular, for every
. In particular, for every  , there exists that cannot be computed by a circuit of size
, there exists that cannot be computed by a circuit of size  .
.
Proof: This is a counting argument. There are 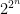 functions , and we claim that the number of circuits of size
functions , and we claim that the number of circuits of size  is at most
is at most  , assuming
, assuming  . To bound the number of circuits of size we create a compact binary encoding of such circuits. Identify gates with numbers
. To bound the number of circuits of size we create a compact binary encoding of such circuits. Identify gates with numbers  . For each gate, specify where the two inputs are coming from, whether they are complemented, and the type of gate. The total number of bits required to represent the circuit is
. For each gate, specify where the two inputs are coming from, whether they are complemented, and the type of gate. The total number of bits required to represent the circuit is

So the number of circuits of size is at most 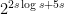 , and this is not sufficient to compute all possible functions if
, and this is not sufficient to compute all possible functions if
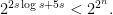
This is satisfied if  and .
and .
The following result shows that efficient computations can be simulated by small circuits.
Theorem 5 If  , then
, then  .
.
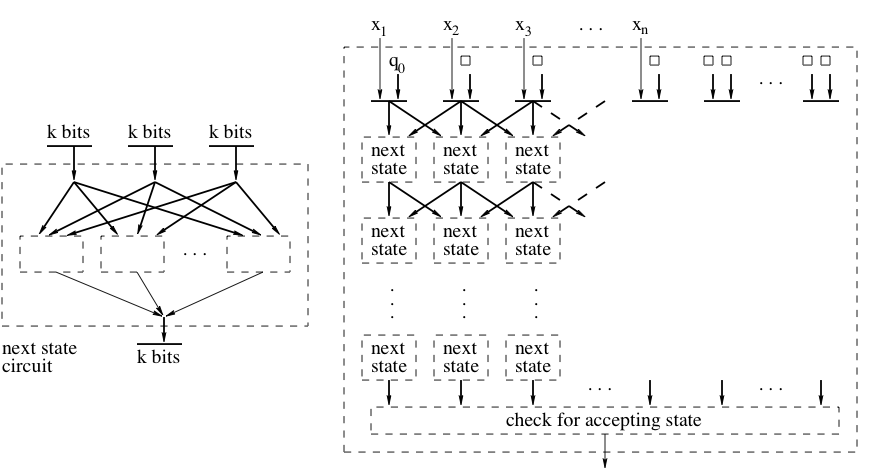
Proof: Let be a decision problem solved by a machine  in time
in time 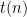 . Fix and s.t. , and consider the
. Fix and s.t. , and consider the 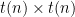 tableau of the computation of
tableau of the computation of 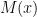 . See the figure below.
. See the figure below.
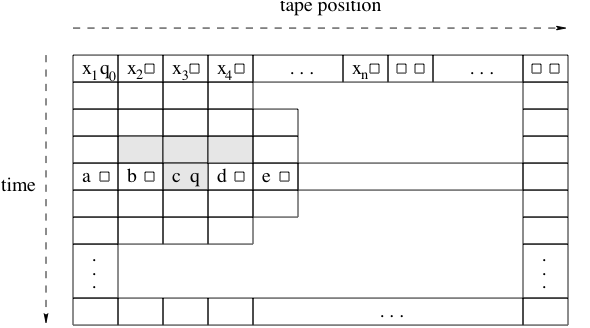
Assume that each entry 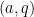 of the tableau is encoded using
of the tableau is encoded using  bits. By Proposition 3, the transition function
bits. By Proposition 3, the transition function  used by the machine can be implemented by a “next state circuit” of size
used by the machine can be implemented by a “next state circuit” of size 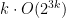 , which is exponential in but constant in . This building block can be used to create a circuit of size
, which is exponential in but constant in . This building block can be used to create a circuit of size  that computes the complete tableau, thus also computes the answer to the decision problem. The complete construction is shown in the figure below.
that computes the complete tableau, thus also computes the answer to the decision problem. The complete construction is shown in the figure below.
Corollary 6  .
.
On the other hand, it’s easy to show that 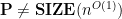 , and, in fact, one can define languages in
, and, in fact, one can define languages in 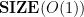 that are undecidable.
that are undecidable.
3. Randomized Algorithms
First we are going to describe the probabilistic model of computation. In this model an algorithm  gets as input a sequence of random bits
gets as input a sequence of random bits  and the ”real” input of the problem. The output of the algorithm is the correct answer for the input with some probability.
and the ”real” input of the problem. The output of the algorithm is the correct answer for the input with some probability.
Definition 7 An algorithm is called a polynomial time probabilistic algorithm if the size of the random sequence  is polynomial in the input
is polynomial in the input 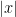 and
and  runs in time polynomial in .
runs in time polynomial in .
If we want to talk about the correctness of the algorithm, then informally we could say that for every input we need ![{\mathop{\mathbb P}[ A(x,r)=\text{correct answer for } x] \geq \frac{2}{3}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+P%7D%5B+A%28x%2Cr%29%3D%5Ctext%7Bcorrect+answer+for+%7D+x%5D+%5Cgeq+%5Cfrac%7B2%7D%7B3%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . That is, for every input the probability distribution over all the random sequences must be some constant bounded away from
. That is, for every input the probability distribution over all the random sequences must be some constant bounded away from 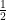 . Let us now define the class BPP.
. Let us now define the class BPP.
Definition 8 A decision problem is in 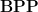 if there is a polynomial time algorithm and a polynomial
if there is a polynomial time algorithm and a polynomial  such that :
such that :
![\displaystyle \forall x\in L \;\;\; \mathop{\mathbb P}_{r\in \{0,1\}^{p(|x|)}}[A(x,r)=1] \geq 2/3](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cforall+x%5Cin+L+%5C%3B%5C%3B%5C%3B+%5Cmathop%7B%5Cmathbb+P%7D_%7Br%5Cin+%5C%7B0%2C1%5C%7D%5E%7Bp%28%7Cx%7C%29%7D%7D%5BA%28x%2Cr%29%3D1%5D+%5Cgeq+2%2F3+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \forall x\not\in L\;\;\; \mathop{\mathbb P}_{r\in \{0,1\}^{p(|x|)}}[A(x,r)=1] \leq 1/3](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cforall+x%5Cnot%5Cin+L%5C%3B%5C%3B%5C%3B+%5Cmathop%7B%5Cmathbb+P%7D_%7Br%5Cin+%5C%7B0%2C1%5C%7D%5E%7Bp%28%7Cx%7C%29%7D%7D%5BA%28x%2Cr%29%3D1%5D+%5Cleq+1%2F3+&bg=ffffff&fg=000000&s=0&c=20201002)
We can see that in this setting we have an algorithm with two inputs and some constraints on the probabilities of the outcome. In the same way we can also define the class P as:
Definition 9 A decision problem is in 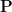 if there is a polynomial time algorithm and a polynomial such that :
if there is a polynomial time algorithm and a polynomial such that :
![\displaystyle \forall x\in L \;\;\; : \mathop{\mathbb P}_{r\in \{0,1\}^{p(|x|)}}[A(x,r)=1] =1](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cforall+x%5Cin+L+%5C%3B%5C%3B%5C%3B+%3A+%5Cmathop%7B%5Cmathbb+P%7D_%7Br%5Cin+%5C%7B0%2C1%5C%7D%5E%7Bp%28%7Cx%7C%29%7D%7D%5BA%28x%2Cr%29%3D1%5D+%3D1&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \forall x\not\in L : \mathop{\mathbb P}_{r\in \{0,1\}^{p(|x|)}}[A(x,r)=1] = 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cforall+x%5Cnot%5Cin+L+%3A+%5Cmathop%7B%5Cmathbb+P%7D_%7Br%5Cin+%5C%7B0%2C1%5C%7D%5E%7Bp%28%7Cx%7C%29%7D%7D%5BA%28x%2Cr%29%3D1%5D+%3D+0+&bg=ffffff&fg=000000&s=0&c=20201002)
Similarly, we define the classes  and ZPP.
and ZPP.
Definition 10 A decision problem is in if there is a polynomial time algorithm and a polynomial such that:
![\displaystyle \forall x\in L \;\;\; \mathop{\mathbb P}_{r\in \{0,1\}^{p(|x|)}}[A(x,r)=1] \geq 1/2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cforall+x%5Cin+L+%5C%3B%5C%3B%5C%3B+%5Cmathop%7B%5Cmathbb+P%7D_%7Br%5Cin+%5C%7B0%2C1%5C%7D%5E%7Bp%28%7Cx%7C%29%7D%7D%5BA%28x%2Cr%29%3D1%5D+%5Cgeq+1%2F2+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \forall x\not\in L \;\;\; \mathop{\mathbb P}_{r\in \{0,1\}^{p(|x|)}}[A(x,r)=1] \leq 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cforall+x%5Cnot%5Cin+L+%5C%3B%5C%3B%5C%3B+%5Cmathop%7B%5Cmathbb+P%7D_%7Br%5Cin+%5C%7B0%2C1%5C%7D%5E%7Bp%28%7Cx%7C%29%7D%7D%5BA%28x%2Cr%29%3D1%5D+%5Cleq+0+&bg=ffffff&fg=000000&s=0&c=20201002)
Definition 11 A decision problem is in  if there is a polynomial time algorithm whose output can be
if there is a polynomial time algorithm whose output can be 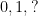 and a polynomial such that :
and a polynomial such that :
![\displaystyle \forall x \;\;\; \mathop{\mathbb P}_{r\in \{0,1\}^{p(|x|)}}[A(x,r)=?] \leq 1/2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cforall+x+%5C%3B%5C%3B%5C%3B+%5Cmathop%7B%5Cmathbb+P%7D_%7Br%5Cin+%5C%7B0%2C1%5C%7D%5E%7Bp%28%7Cx%7C%29%7D%7D%5BA%28x%2Cr%29%3D%3F%5D+%5Cleq+1%2F2+&bg=ffffff&fg=000000&s=0&c=20201002)

4. Relations between complexity classes
After defining these probabilistic complexity classes, let us see how they are related to other complexity classes and with each other.
Theorem 12 RP NP.
NP.
Proof: Suppose we have a algorithm for a language . Then this algorithm is can be seen as a “verifier” showing that is in NP. If 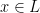 then there is a random sequence , for which the algorithm answers yes, and we think of such sequences as witnesses that
then there is a random sequence , for which the algorithm answers yes, and we think of such sequences as witnesses that 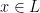 . If
. If 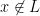 then there is no witness.
then there is no witness.
We can also show that the class ZPP is no larger than RP.
Theorem 13 ZPPRP.
Proof: We are going to convert a ZPP algorithm into an RP algorithm. The construction consists of running the ZPP algorithm and anytime it outputs  , the new algorithm will answer
, the new algorithm will answer  . In this way, if the right answer is , then the algorithm will answer with probability
. In this way, if the right answer is , then the algorithm will answer with probability  . On the other hand, when the right answer is , then the algorithm will give the wrong answer with probability less than
. On the other hand, when the right answer is , then the algorithm will give the wrong answer with probability less than  , since the probability of the ZPP algorithm giving the output is less than .
, since the probability of the ZPP algorithm giving the output is less than .
Another interesting property of the class ZPP is that it’s equivalent to the class of languages for which there is an average polynomial time algorithm that always gives the right answer. More formally,
Theorem 14 A language is in the class if and only if has an average polynomial time algorithm that always gives the right answer.
Proof: First let us clarify what we mean by average time. For each input we take the average time of  over all random sequences . Then for size we take the worst time over all possible inputs of size
over all random sequences . Then for size we take the worst time over all possible inputs of size  . In order to construct an algorithm that always gives the right answer we run the algorithm and if it outputs a , then we run it again. Suppose that the running time of the algorithm is
. In order to construct an algorithm that always gives the right answer we run the algorithm and if it outputs a , then we run it again. Suppose that the running time of the algorithm is  , then the average running time of the new algorithm is:
, then the average running time of the new algorithm is:
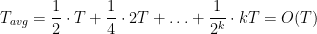
Now, we want to prove that if the language has an algorithm that runs in polynomial average time  , then this is in ZPP. We run the algorithm for time
, then this is in ZPP. We run the algorithm for time  and output a if the algorithm has not yet stopped. It is straightforward to see that this belongs to ZPP. First of all, the worst running time is polynomial, actually . Moreover, the probability that our algorithm outputs a is less than , since the original algorithm has an average running time and so it must stop before time at least half of the times.
and output a if the algorithm has not yet stopped. It is straightforward to see that this belongs to ZPP. First of all, the worst running time is polynomial, actually . Moreover, the probability that our algorithm outputs a is less than , since the original algorithm has an average running time and so it must stop before time at least half of the times.
Let us now prove the fact that is contained in BPP.
Theorem 15 RPBPP
Proof: We will convert an algorithm into a algorithm. In the case that the input does not belong to the language then the algorithm always gives the right answer, so it certainly satisfies that requirement of giving the right answer with probability at least  . In the case that the input does belong to the language then we need to improve the probability of a correct answer from at least to at least .
. In the case that the input does belong to the language then we need to improve the probability of a correct answer from at least to at least .
Let be an RP algorithm for a decision problem . We fix some number and define the following algorithm:
- input: ,
- pick
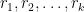
- if
 then return 0
then return 0
- else return 1
Let us now consider the correctness of the algorithm. In case the correct answer is the output is always right. In the case where the right answer is the output is right except when all  .
.
![\displaystyle \text{if} \;\;\;x\not\in L\;\;\; \mathop{\mathbb P}_{r_1,\ldots,r_k}[A^k(x,r_1,\ldots,r_k)=1] = 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctext%7Bif%7D+%5C%3B%5C%3B%5C%3Bx%5Cnot%5Cin+L%5C%3B%5C%3B%5C%3B+%5Cmathop%7B%5Cmathbb+P%7D_%7Br_1%2C%5Cldots%2Cr_k%7D%5BA%5Ek%28x%2Cr_1%2C%5Cldots%2Cr_k%29%3D1%5D+%3D+0+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \text{if}\;\;\; x\in L\;\;\; \mathop{\mathbb P}_{r_1,\ldots,r_k}[A^k(x,r_1,\ldots,r_k)=1] \geq 1-\left(\dfrac{1}{2}\right)^k](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctext%7Bif%7D%5C%3B%5C%3B%5C%3B+x%5Cin+L%5C%3B%5C%3B%5C%3B+%5Cmathop%7B%5Cmathbb+P%7D_%7Br_1%2C%5Cldots%2Cr_k%7D%5BA%5Ek%28x%2Cr_1%2C%5Cldots%2Cr_k%29%3D1%5D+%5Cgeq+1-%5Cleft%28%5Cdfrac%7B1%7D%7B2%7D%5Cright%29%5Ek+&bg=ffffff&fg=000000&s=0&c=20201002)
It is easy to see that by choosing an appropriate the second probability can go arbitrarily close to . In particular, choosing  suffices to have a probability larger than , which is what is required by the definition of BPP. In fact, by choosing to be a polynomial in , we can make the probability exponentially close to . This means that the definition of that we gave above would have been equivalent to a definition in which, instead of the bound of for the probability of a correct answer when the input is in the language , we had have a bound of
suffices to have a probability larger than , which is what is required by the definition of BPP. In fact, by choosing to be a polynomial in , we can make the probability exponentially close to . This means that the definition of that we gave above would have been equivalent to a definition in which, instead of the bound of for the probability of a correct answer when the input is in the language , we had have a bound of  , for a fixed polynomial
, for a fixed polynomial  .
.
Let, now, A be a BPP algorithm for a decision problem . Then, we fix and define the following algorithm:
- input:
- pick
-

- if
 then return 1
then return 1
- else return 0
In a BPP algorithm we expect the right answer to come up with probability more than . So, by running the algorithm many times we make sure that this slightly bigger than probability will actually show up in the results.
We will prove next time that the error probability of algorithm 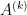 is at most
is at most  .
.

