
Today we show how to reduce the error probability of probabilistic algorithms, prove Adleman’s theorem that polynomial time probabilistic algorithms can be simulated by polynomial size circuits, and we give the definition of the polynomial hierarchy
1. Adleman’s Theorem
Last time we mentioned that if we start from a randomized algorithm that provides the correct answer only with probability slightly higher than half, then repeating the algorithm many times with independent randomness will make the right answer appear the majority of the times with very high probability.
More formally, we have the following theorem.
Theorem 1 (Chernoff Bound) Suppose
are independent random variables with values in
and for every
,
. Then, for any
:
![\displaystyle \mathop{\mathbb P} \left[ \sum_{i=1}^k X_i> \sum_{i=1}^k p_i + k \epsilon \right] <e^{-2\epsilon^2 k}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D+%5Cleft%5B+%5Csum_%7Bi%3D1%7D%5Ek+X_i%3E+%5Csum_%7Bi%3D1%7D%5Ek+p_i+%2B+k+%5Cepsilon+%5Cright%5D+%3Ce%5E%7B-2%5Cepsilon%5E2+k%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\mathbb P} \left[ \sum_{i=1}^k X_i < \sum_{i=1}^k p_i - k \epsilon \right]<e^{-2\epsilon^2k}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D+%5Cleft%5B+%5Csum_%7Bi%3D1%7D%5Ek+X_i+%3C+%5Csum_%7Bi%3D1%7D%5Ek+p_i+-+k+%5Cepsilon+%5Cright%5D%3Ce%5E%7B-2%5Cepsilon%5E2k%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The Chernoff bounds will enable us to bound the probability that our result is far from the expected. Indeed, these bounds say that this probability is exponentially small with respect to 
Let us now consider how the Chernoff bounds apply to the algorithm we described previously. We fix the input 
![{p=\mathop{\mathbb P}_{r}[A(x,r)=1]}](https://s0.wp.com/latex.php?latex=%7Bp%3D%5Cmathop%7B%5Cmathbb+P%7D_%7Br%7D%5BA%28x%2Cr%29%3D1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
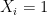

First, suppose 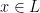


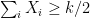

We now apply the Chernoff bounds to bound this probability.
![\displaystyle \mathop{\mathbb P}[A^{(k)} \text{outputs the wrong answer on}\;\;x]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D%5BA%5E%7B%28k%29%7D+%5Ctext%7Boutputs+the+wrong+answer+on%7D%5C%3B%5C%3Bx%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = \mathop{\mathbb P}[\sum_{i}X_i< \tfrac{k}{2}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D+%5Cmathop%7B%5Cmathbb+P%7D%5B%5Csum_%7Bi%7DX_i%3C+%5Ctfrac%7Bk%7D%7B2%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \leq \mathop{\mathbb P}[\sum_{i}X_i-kp\leq -\tfrac{k}{6}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cleq+%5Cmathop%7B%5Cmathbb+P%7D%5B%5Csum_%7Bi%7DX_i-kp%5Cleq+-%5Ctfrac%7Bk%7D%7B6%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002)

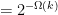
The probability is exponentially small in 
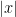
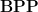

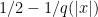


Would it be equivalent to have a bound of 
Definition 2
is the set of problems that can be solved by a nondeterministic Turing machine in polynomial time where the acceptance condition is that a majority (more than half) of computation paths accept.
Although superficially similar to 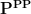


Now, we are going to see how the probabilistic complexity classes relate to circuit complexity classes and specifically prove that the class
Theorem 3 (Adleman)
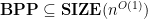
Proof: Let 


![\displaystyle \mathop{\mathbb P}_{r\in \{0,1\}^{p(|x|)}}[A(x,r)=\text{wrong answer for} \;\;\;x] \leq 2^{-(n+1)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D_%7Br%5Cin+%5C%7B0%2C1%5C%7D%5E%7Bp%28%7Cx%7C%29%7D%7D%5BA%28x%2Cr%29%3D%5Ctext%7Bwrong+answer+for%7D+%5C%3B%5C%3B%5C%3Bx%5D+%5Cleq+2%5E%7B-%28n%2B1%29%7D&bg=ffffff&fg=000000&s=0&c=20201002)
This follows from our previous conclusion that we can replace 

Claim 1 There is a random sequence
such that for every
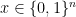
is correct.
Proof: Informally, we can see that, for each input 

![\displaystyle \mathop{\mathbb P}_{r}[\text{for every}\;\;\; x, A(x,r)\;\;\;\text{is correct}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D_%7Br%7D%5B%5Ctext%7Bfor+every%7D%5C%3B%5C%3B%5C%3B+x%2C+A%28x%2Cr%29%5C%3B%5C%3B%5C%3B%5Ctext%7Bis+correct%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle = 1-\mathop{\mathbb P}_{r}[\exists x, A(x,r)\;\;\; \text{is wrong}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D+1-%5Cmathop%7B%5Cmathbb+P%7D_%7Br%7D%5B%5Cexists+x%2C+A%28x%2Cr%29%5C%3B%5C%3B%5C%3B+%5Ctext%7Bis+wrong%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
The probability in the second expression is the union of 
![\displaystyle \geq 1- \sum_{x\in\{0,1\}^n}\mathop{\mathbb P}_{r}[A(x,r) \text{is wrong}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cgeq+1-+%5Csum_%7Bx%5Cin%5C%7B0%2C1%5C%7D%5En%7D%5Cmathop%7B%5Cmathbb+P%7D_%7Br%7D%5BA%28x%2Cr%29+%5Ctext%7Bis+wrong%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002)

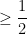
So, we proved that at least half of the random sequences are correct for all possible input 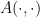

All we have to do is find a random sequence which is always correct and build it inside the circuit. Hence, our circuit will take as input only the input

In general, the hierarchy of complexity classes looks like the following picture, if we visualize all classes that are not known to be equal as distinct.

It is, however, generally conjectured that 

2. Complexity Classes with Advice
In this section we prove an alternative characterization of classes of functions computable by bounded-size circuits.
Let 

Definition 4
is the class of decision problems such there is a sequence of strings
where
, and a polynomial-time algorithm
correctly solves the problem.
Definition 5

Theorem 6

Proof: For any problem in 
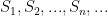
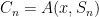
For any problem in 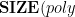

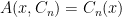
3. Polynomial hierarchy
Remark 1 (Definition of
) A problem is in
and a polynomial time bound
such that


The polynomial hierarchy starts with familiar classes on level one: 

Definition 7
is the class of all problems such that there is a polynomial time computable
and k polynomials
such that

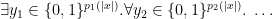

Definition 8
is the class of all problems such that there is a polynomial time computable


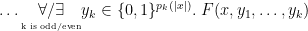
One thing that is easy to see is that 

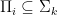
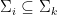

Exercise 1
has a complete problem.
Next time we will prove (a stronger version of) the following result:
Theorem 9 If
, then
,
.

Thanks for the posts. Just one thing: the simplification of the complexity map, after assuming P = BPP, is not reflected in the posted picture.
The two figures are the same.