
In this lecture we prove the Karp-Lipton theorem that if all NP problems have polynomial size circuits then the polynomial hierarchy collapses. A nice application is a theorem of Kannan, showing that, for every 
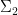

1. The Karp-Lipton Theorem
Theorem 1 (Karp-Lipton) If
then
and therefore the polynomial hierarchy would collapse to its second level.
Before proving the above theorem, we first show a result that contains some of the ideas in the proof of the Karp-Lipton theorem.
Lemma 2 If
and every polynomial
, there is a family of polynomial size circuits such that

Proof: We define the circuits 




Also, each circuit realizes an NP computation, and so it can be built of polynomial size. Consider now the sequence 

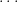
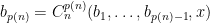

The reader should be able to convince himself that this is a satisfying assignment for 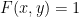

We now prove the Karp-Lipton theorem.
Proof: } We will show that if 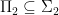

Let 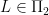


By using Lemma 2, we can show that, for every 


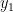


Let 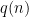
So now we have that for inputs

which shows that 
2. Kannan’s Theorem
Although it is open to prove that the polynomial hierarchy is not contained in 
Theorem 3 For every polynomial
, there is a language
such that
.
Note that Theorem is not saying that 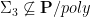



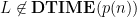
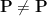
Kannan observed the following consequence of Theorem 2 and of the Karp-Lipton theorem.
Theorem 4 For every polynomial
such that
Proof: We consider two cases:
- if
; then we are done because
.
- if
, then
, so by the Karp-Lipton theorem we have
, and the language
given by Theorem 2 is in
3. The Valiant-Vazirani Theorem
In this section we show the following: suppose there is an algorithm for the satisfiability problem that always find a satisfying assignment for formulae that have exactly one satisfiable assignment (and behaves arbitrarily on other instances): then we can get an RP algorithm for the general satisfiability problem, and so 
We prove the result by presenting a randomized reduction that given in input a CNF formula 
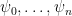

The idea for the reduction is the following. Suppose 

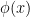

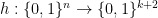



Definition 5 Let
be a family of functions of the form
. We say that
and for every two possible outputs
we have
![\displaystyle \mathop{\mathbb P}_{h\in H} [h(x)=a \wedge h(y)=b] = \frac 1 {2^{2m}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D_%7Bh%5Cin+H%7D+%5Bh%28x%29%3Da+%5Cwedge+h%28y%29%3Db%5D+%3D+%5Cfrac+1+%7B2%5E%7B2m%7D%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Another way to look at the definition is that for every 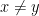



![{\mathop{\mathbb P}_h[h(x)=a | h(y)=b] = \mathop{\mathbb P}_h[h(x)=a]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+P%7D_h%5Bh%28x%29%3Da+%7C+h%28y%29%3Db%5D+%3D+%5Cmathop%7B%5Cmathbb+P%7D_h%5Bh%28x%29%3Da%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
For 
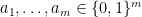






Thanks again.
Are pdfs of these lecture notes available? I noticed that the handout at http://theory.stanford.edu/~trevisan/cs254-10/lecture06.pdf is missing Kannan’s theorem.
I have made all the corrections that people have suggested in past comments (thanks to all!) and synchronized the pdf files with the versions posted here
No proof of Theorem 3? =(
Also, a small typo: all occurrences of “Theorem 2” should be “Theorem 3”
Regarding Theorem 3, Kannan first argues directly about \Sigma_4 (not \Sigma_3). Or is there a similarly easy argument that applies to \Sigma_3?
I don’t know what’s the original proof of Kannan, but consider the language where, on input x of length n, I output h(x), where h() is the lexicographically first function among those that (i) depend only on the first 2klog n bits of the input and (ii) have circuit complexity > n^k.
Then the language is in , because it is formulated as
, because it is formulated as
if and only if
there exists an h (specified as a truth-table of a function on 2klog n bits) such that:
1) for all circuits C of size less than n^k (operating on 2klog n input bits), C and h compute different functions;
2) for all functions g smaller than h in lexicographic order, there exists a circuit C of size less than n^k (operating on 2klog n input bits) such that g and C compute the same function
note that you can check in deterministic polynomial time whether C and g compute the same function.
What was Kannan’s proof?
What was Kannan’s proof?
The same, except that he looked at functions on n-bit inputs and so (essentially) used another alternation to check whether C and g compute the same function.