I would like to comment on two questions I have read on the theoretical computer science Q&A site.
Boris Bukh asks a rather novel question about the complexity of Max 3SAT. Given a 3CNF formula  , we know it is NP-hard to approximate the maximum number
, we know it is NP-hard to approximate the maximum number 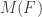 of clauses that can be simultaneously satisfied. But how many bits of information can we efficiently compute about
of clauses that can be simultaneously satisfied. But how many bits of information can we efficiently compute about 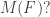 Put another way, how many possible values of can we efficiently rule out? If the formula has
Put another way, how many possible values of can we efficiently rule out? If the formula has  clauses, then we know that the possible value of is one of
clauses, then we know that the possible value of is one of  possible values, but it is difficult to see how this can be narrowed down much more. On the other hand, there is an argument that you cannot narrow the set of possible values down to a constant, or even a constant times
possible values, but it is difficult to see how this can be narrowed down much more. On the other hand, there is an argument that you cannot narrow the set of possible values down to a constant, or even a constant times  , unless the polynomial hierarchy collapses. But there is still a big gap.
, unless the polynomial hierarchy collapses. But there is still a big gap.
John Sidles asks a series of questions that are nominally related to  but that can also be phrased about the proof that, say, every problem in
but that can also be phrased about the proof that, say, every problem in  has a uniform family of polynomial size circuits.
has a uniform family of polynomial size circuits.
In the latter setting, we start by showing that from a Turing machine  , a time bound
, a time bound  , and a size bound
, and a size bound  , we can construct a circuit of size polynomial in , , and the size of , such that on every input
, we can construct a circuit of size polynomial in , , and the size of , such that on every input  of length the circuit simulates what the Turing machine does on input for steps. If a language
of length the circuit simulates what the Turing machine does on input for steps. If a language  is in , then there is a Turing machine and a polynomial bound
is in , then there is a Turing machine and a polynomial bound 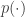 such that decides on every input of length in time at most
such that decides on every input of length in time at most  ; given , we can then construct a circuit that solves on inputs of length by applying the circuit simulation with
; given , we can then construct a circuit that solves on inputs of length by applying the circuit simulation with  .
.
But, the question is, what if we do not know ? This might sound like a rather strange issue, like someone objecting to the commutative property of addition by saying, how I am going to use  if I do not know and
if I do not know and  ?
?
There is, however, a real issue, and one that often confuses students, which is the “non-constructive” nature of the definition of complexity classes. That is, a language belongs to if there exists an algorithm and there exists a polynomial time bound such that the algorithm is correct and always terminates within the time bound. The definition does not require that we know the algorithm and the time bound. It might seem that of course it does not, because “we” and “know” are not mathematical concepts, but consider the following example.
Let 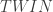 be the language of integers such that there is a pair of twin primes larger than . Is this problem in ? Of course! What is the algorithm? Well, I don’t know, although I can exhibit an infinite list of possible algorithm, and prove that all of them work in linear time and that at least one of them is correct. Less artificially, the Robertson-Seymour theory gives polynomial time algorithms for graph properties that are closed under minors, but to construct an algorithm for such a property one needs to know the finite set of obstruction, and there is no general way to find such a set, even in principle.
be the language of integers such that there is a pair of twin primes larger than . Is this problem in ? Of course! What is the algorithm? Well, I don’t know, although I can exhibit an infinite list of possible algorithm, and prove that all of them work in linear time and that at least one of them is correct. Less artificially, the Robertson-Seymour theory gives polynomial time algorithms for graph properties that are closed under minors, but to construct an algorithm for such a property one needs to know the finite set of obstruction, and there is no general way to find such a set, even in principle.
If is meant to model problems that can be efficiently solved, does it make sense for the definition to allow problems such as the ones above that we do not, in fact, know how to solve efficiently?
An alternative would be to work with “constructive ”, let’s call it  , that is, the class of languages that have polynomial time algorithms such that the correctness and time-boundedness of the algorithm are provable, say, in ZFC. Now if someone tells us that a given problem is in we can, at least in principle, find the algorithm and time bound. Constructive definitions could be given for all complexity classes.
, that is, the class of languages that have polynomial time algorithms such that the correctness and time-boundedness of the algorithm are provable, say, in ZFC. Now if someone tells us that a given problem is in we can, at least in principle, find the algorithm and time bound. Constructive definitions could be given for all complexity classes.
Why don’t we work with the constructive definitions? I think that one problem is that they introduce ugliness, unnecessary dependencies on certain choices (why ZFC and not ZF, or what about large cardinal axioms?), to address one of the most benign ways in which the formal definitions of complexity classes deviate from their intuitive meaning.
But more importantly, while a constructive inclusion is a more satisfactory statement than the non-constructive analog, there is something unsettling about a separation from a constructive class. Suppose, for example, that there is a proof that SAT is not in . Such a proof would still leave open the possibility that SAT allows a fast algorithm, it’s just that the correctness and efficiency of the algorithm cannot be proved. But it could even be that we discover such an algorithm, verify that it works well in practice, and reap all the practical benefits of 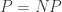 , so in this case the constructive definition does not capture what is going in “practice.”
, so in this case the constructive definition does not capture what is going in “practice.”
One could then say that the “right” way of proving  is to show that for every correct algorithm for SAT we can prove an explicit superpolynomial time lower bound. Or should it be, for every polynomial time algorithm we can explicitly find infinitely many inputs on which the program is wrong? Should this be required of all algorithms or all the ones for which correctness or time bound are themselves provable?
is to show that for every correct algorithm for SAT we can prove an explicit superpolynomial time lower bound. Or should it be, for every polynomial time algorithm we can explicitly find infinitely many inputs on which the program is wrong? Should this be required of all algorithms or all the ones for which correctness or time bound are themselves provable?
Very quickly, we fall into the mathematical rabbit hole of intuitionistic logic, in which the negation of the negation of a statement  is not the same thing as statement .
is not the same thing as statement .


Is it known whether constructive P equals P?
Sorry, let me re-phrase my question to be more precise. Is it known whether there is an algorithm that runs in polynomial time, but it is not provable that the algorithm runs in polynomial time (say, in PA or ZFC)? This seems like something that could reasonably be true. Whether its “correctness” is provable would depend on what we want the algorithm to do and whether that is expressible as a logical statement. For natural NP problems certainly correctness would be an issue, since the formal statement of the problem would be separate from the algorithm that decides it, and it would be non-trivial to connect the two by a proof. However, I can imagine constructing some problem by diagonalization solely for the purpose of being decidable in polynomial time (but the diagonalizing algorithm is not provably polynomial time). In this case, “correctness” is a moot point: the algorithm decides whatever problem it decides, and we don’t care what that problem is.
A harder question would be this: Is there a problem decidable in polynomial time, but there is no proof that it is decidable in polynomial time? This is the cP=P question, if cP is the set of problems solvable by some provably polynomial-time algorithm (again, correctness is a non-issue for unnatural problems). In this case, it could be that some polynomial time algorithms are not provably polynomial time, but in each case some (possibly slower) polynomial time algorithm decides the same problem.
I think that you can argue that there are problems in P for which there are no provably correct algorithm as follows.
For every binary string , let
, let 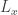 be the language that contains all integers
be the language that contains all integers  such that the Kolmogorov complexity of
such that the Kolmogorov complexity of  is smaller than
is smaller than  . Then, for every
. Then, for every  , the language
, the language 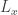 is in
is in  , because it is solved by an algorithm that on input
, because it is solved by an algorithm that on input  outputs “accept” if and only if
outputs “accept” if and only if  , where
, where  is hard-wired into the algorithm.
is hard-wired into the algorithm.
There is an absolute constant such that, in ZFC, no statement of the form “the Kolmogorov complexity of the following binary string […] is more than $c$” is provable.
such that, in ZFC, no statement of the form “the Kolmogorov complexity of the following binary string […] is more than $c$” is provable.
Now suppose toward a contradiction that all languages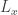 were in P with a provably correct and efficient algorithm. Take a string
were in P with a provably correct and efficient algorithm. Take a string  such that
such that  . Consider the algorithm
. Consider the algorithm  that provably and efficiently solve
that provably and efficiently solve 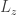 . Then
. Then  on input
on input  rejects, and so the computation of
rejects, and so the computation of  on input
on input  , together with the proof of correctness of
, together with the proof of correctness of  , proves the statement
, proves the statement  in ZFC, which is a contradiction.
in ZFC, which is a contradiction.
So this means that there is some (in fact, any
(in fact, any  of sufficiently high Kolmogorov complexity will do) such that
of sufficiently high Kolmogorov complexity will do) such that 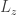 is solvable in polynomial time, but it has no provably correct polynomial time algorithm.
is solvable in polynomial time, but it has no provably correct polynomial time algorithm.
Hi Luca:
I understand your argument. But my point is that running time can be considered independently of correctness, and I think that it should be considered independently so as to meaningfully define a class like cP. One can define cP with respect to provable running time but I don’t see how to define cP with respect to correctness.
Say that x is some large random string with K(x) = 173 (and that 173 is large enough for the unprovability of “K(x) >= 173” to kick in). In your example, correctness is defined not with respect to the algorithm A, or even with respect to the language L_x (which can equivalently be written {k | k >= 173}), but with respect to your “intention” that 173 be the Kolmogorov complexity of some string. We can just as well state that for A to operate correctly, it must accept precisely those integers k >= 173. A does this, and we can prove that it does this. What we cannot do is prove that 173 is a lower bound for the Kolmogorov complexity of any string, but that’s not the “fault” or A or L_x. Conversely, I can take an algorithm A and contort its statement of “correctness criteria” so that, if “correct(A)” was the original true and provable statement that A works correctly, the new statement is “correct(A) and K(x) >= 173”. The new statement of correctness is still true but has become unprovable. Is A provably correct or not? It depends on what we mean by “correct”, not only on some intrinsic property of A (unlike its running time, which is in fact an intrinsic property of A).
If M is a Turing machine, write poly(M) to denote the statement that M halts on all inputs in polynomial time, and write prov(M) to denote the statement that M provably (say, in ZFC) halts on all inputs in polynomial time. Using my definition, cP = P if and only if, for all M, poly(M) => prov(M). I’m not sure how to define cP to also account for “correctness”.
For constructivity there is indeed a question of what the “right” notion of an axiomatization should be because one can always add extra axioms for any consistent statement. However, there is a natural way to ground the whole process which is to try to use a “minimal”/”weakest” convenient formal system that fully captures a given complexity class (in the sense that each element of the class can be associated with some corresponding true statement in the theory) . A goal of this process is to try to find easier versions of the separation questions for our favorite complexity classes since provability of statements in these weak theories would imply existence of efficient algorithms (but not vice-versa). There is a sizable line of work attempting to do just this. The best place to see this is Steve Cook and Phong Nguyen’s book on proof complexity (also available in draft form on Cook’s web page) which is quite comprehensive in these aspects.
Hi Dave,
I missed the point of your earlier question. You can definitely have a polynomial time algorithm A that decides a language L, and such that the polynomial running time of A is not provable, say, in ZFC. To see an artificial example, suppose that A has an instruction that says that if the input x is a proof that a certain random string z hard-wired into the program has kolmogorov complexity less than 173, then the algorithm will do something that takes time , and then resume the computation. If the Kolmogorov complexity of z is less than 173 then this will happen infinitely often, and so to prove the polynomial running time you have to prove that the Kolmogorov complexity of z is more than 173, which is not possible. (Instead of 173, one needs to use the right number for ZFC)
, and then resume the computation. If the Kolmogorov complexity of z is less than 173 then this will happen infinitely often, and so to prove the polynomial running time you have to prove that the Kolmogorov complexity of z is more than 173, which is not possible. (Instead of 173, one needs to use the right number for ZFC)
But I think that the right question is, can there be a language in P such that for all its polynomial time algorithms, the polynomial running time is unprovable? Here the answer is no, because if A is a polynomial time algorithm for L that runs in time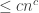 on every input of length n, then there is an algorithm A’ for L of provable polynomial time: A’, on input x of length n, simulates A for
on every input of length n, then there is an algorithm A’ for L of provable polynomial time: A’, on input x of length n, simulates A for  steps, If the simulation does not halt within so many steps, A’ rejects. The termination condition is never reached, so A’ and A define the same language, but now it is easy to prove that A’ runs in polynomial.
steps, If the simulation does not halt within so many steps, A’ rejects. The termination condition is never reached, so A’ and A define the same language, but now it is easy to prove that A’ runs in polynomial.
What is not easy, and in fact impossible if A had an unprovable running time, is to establish that A and A’ decide the same language, so in a sense running time provability reduces to correctness.
Now you raise a good point that I could define L to be the language decided by A’, and now I get, for every problem in P, a provably correct and provably fast algorithm.
Which means, I guess, that if we want to talk about constructive results we need to distinguish between a language and its several possible equivalent definitions, that is, we shouldn’t say “language L is in constructive P”, but “the set of strings x such that F(x) is true, where F(.) is a logical formula, is in constructive P”, and although all languages in P have a definition according to which they are in constructive P, this is not true for all definitions.
Hi Luca:
Thanks for the answers. Both seem obvious now, of course. 🙂 And I understand better what you mean by constructive P.
Please let me extend my thanks to Dave Doty and Luca Trevisan. I have only today become aware of this exchange, thanks to Sasho Nikolov’s answer to my TCS StackExchange question “Does P contain languages decided solely by incomprehensible TMs?”.
It will take awhile to assimilate these comments, but eventually (I’m sure) they will help me post my question more rigorously, clearly, and interestingly.
For which, thank you both again.
Pingback: Does P contain languages whose existence is independent of PA or ZFC? (TCS community wiki) | Question and Answer
Pingback: Does P contain incomprehensible languages? (TCS community wiki) | Question and Answer