Readers of in theory have heard about Cheeger’s inequality a lot. It is a relation between the edge expansion (or, in graphs that are not regular, the conductance) of a graph and the second smallest eigenvalue of its Laplacian (a normalized version of the adjacency matrix). The inequality gives a worst-case analysis of the “sweep” algorithm for finding sparse cuts, it shows a necessary and sufficient for a graph to be an expander, and it relates the mixing time of a graph to its conductance.
Readers who have heard this story before will recall that a version of this result for vertex expansion was first proved by Alon and Milman, and the result for edge expansion appeared in a paper of Dodzuik, all from the mid-1980s. The result, however, is not called Cheeger’s inequality just because of Stigler’s rule: Cheeger proved in the 1970s a very related result on manifolds, of which the result on graphs is the discrete analog.
So, what is the actual Cheeger’s inequality?
Theorem 1 (Cheeger’s inequality) Let  be an
be an  -dimensional smooth, compact, Riemann manifold without boundary with metric
-dimensional smooth, compact, Riemann manifold without boundary with metric  , let
, let 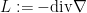 be the Laplace-Beltrami operator on , let
be the Laplace-Beltrami operator on , let 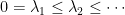 be the eigenvalues of
be the eigenvalues of  , and define the Cheeger constant of to be
, and define the Cheeger constant of to be
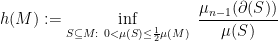
where the  is the boundary of
is the boundary of  ,
,  is the -dimensional measure, and
is the -dimensional measure, and 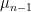 is
is 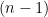 -th dimensional measure defined using . Then
-th dimensional measure defined using . Then

The purpose of this post is to describe to the reader who knows nothing about differential geometry and who does not remember much multivariate calculus (that is, the reader who is in the position I was in a few weeks ago) what the above statement means, to describe the proof, and to see that it is in fact the same proof as the proof of the statement about graphs.
In this post we will define the terms appearing in the above theorem, and see their relation with analogous notions in graphs. In the next post we will see the proof.
First we recall the definitions in the case of graphs, which are good “models” to keep in mind as we will give the definitions of a manifold and of the Laplacian of a manifold.
Let 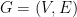 be a
be a  -regular graph and
-regular graph and  be the adjacency matrix of
be the adjacency matrix of  . If
. If 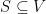 is a subset of vertices, its volume
is a subset of vertices, its volume  is defined as the sum of the degrees of the elements of ,
is defined as the sum of the degrees of the elements of ,  . The boundary of is the set of edges that have one endpoint in and one endpoint in
. The boundary of is the set of edges that have one endpoint in and one endpoint in  ; the conductance of is
; the conductance of is

and the conductance of is defined as

The Laplacian matrix of is defined as  , where is the adjacency matrix of . Since is a symmetric real matrix, all its eigenvalues are real, and, if we call them
, where is the adjacency matrix of . Since is a symmetric real matrix, all its eigenvalues are real, and, if we call them 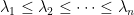 , the Cheeger inequality in graphs is
, the Cheeger inequality in graphs is

1. Manifolds, gradient, and divergence
1.1. What is a manifold?
First let us discuss (non-rigorously) what is a manifold: we can think of an -dimensional manifold as a subset 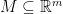 , for some
, for some  , such that for every point
, such that for every point  , if we look at a small ball around
, if we look at a small ball around  , the intersection of the ball with looks like a ball in
, the intersection of the ball with looks like a ball in  . For example, consider a two-dimensional sphere in
. For example, consider a two-dimensional sphere in 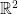 : for every point on the sphere, a small neighborhood around it looks like a flat disc.
: for every point on the sphere, a small neighborhood around it looks like a flat disc.
The formalization of this notion, which will turn out not to require us to think of as a subset of  is rather technical, and it has quite a lot of pieces. Instead of introducing the rigorous definition piece by piece, and trying to understand what a manifold is, I think it’s better to start by thinking about what a manifold does, that is, what kind of properties we want from the definition, and what kind of calculations we want the definition to allow, and then the details of the definition is just whatever works to capture these intentions.
is rather technical, and it has quite a lot of pieces. Instead of introducing the rigorous definition piece by piece, and trying to understand what a manifold is, I think it’s better to start by thinking about what a manifold does, that is, what kind of properties we want from the definition, and what kind of calculations we want the definition to allow, and then the details of the definition is just whatever works to capture these intentions.
Basically, we would like to be able to do with an -dimensional manifold most of the things we would do with . We would like to have a distance function 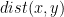 between elements
between elements 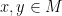 that satisfies the triangle inequality and that is the “length of the shortest path” from to
that satisfies the triangle inequality and that is the “length of the shortest path” from to  in , we would like to have a measure , that gives us the “volume”
in , we would like to have a measure , that gives us the “volume” 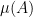 of a subset
of a subset 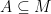 . If we define functions
. If we define functions  , we would like to integrate them, and compute
, we would like to integrate them, and compute 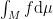 , or
, or 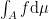 , where . We would also like to have a definition of continuous functions , or
, where . We would also like to have a definition of continuous functions , or  , or
, or 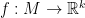 , and, finally, we would like to define derivatives of functions .
, and, finally, we would like to define derivatives of functions .
On the other hand, we will not try to think of the elements of as vectors, and, in particular, we will not have a definition of adding elements of , or multiplying them by constants, much less of taking an inner product of them. (This means that the distance function will not come from a norm.) To see why not, consider a 2-dimensional sphere in 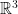 . We want to think of it as completely symmetric under rotations, so there can be no meaningful notion of a point on the sphere being “bigger” than another, so if is a point on the sphere, there isn’t a meaningful notion of
. We want to think of it as completely symmetric under rotations, so there can be no meaningful notion of a point on the sphere being “bigger” than another, so if is a point on the sphere, there isn’t a meaningful notion of 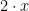 . (You could try to say
. (You could try to say 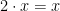 , but then this would imply
, but then this would imply  .)
.)
Because a manifold is not a vector space, it is tricky to define derivatives. We want to think of an -dimensional manifold as a generalization of , and a function 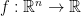 does not have a derivative. Instead, for every direction , it has a partial derivative at in the direction
does not have a derivative. Instead, for every direction , it has a partial derivative at in the direction

and the above expression requires us to add elements of and to multiply them by constants.
However, if we look at a point , the immediate neighborhood of does look like a small piece of , which is a vector space. To make this intuition formal, instead of trying to formalize the notion of “small piece of a vector space,” one defines directional derivatives where the direction is not in but in the tangent space to at , which is a honest-to-God vector space.
In the rigorous definition, we have a topology on , which allows to talk about “small intervals around” a point , and to talk about “continuous functions” 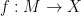 where
where  can be
can be 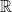 ,
, 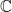 ,
, 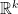 , and so on. Then, for every small interval around a point we have an -dimensional coordinate system, which we can think of as an approximation of the interval around as a piece of ; these coordinate systems are called “charts” and their collection is called an “atlas.” Charts of nearby points are supposed to be “consistent in their intersection,” which is assured by consistent mappings between them. For every point we also have an -dimensional vector space, which is the tangent space at . There are also mapping that relate the tangent spaces of nearby points. Finally, we have a “metric,” that, to make things more confusing, is not a distance function that satisfies the triangle inequality, but is the definition of an inner product between vectors of the tangent spaces. From the metric, it is possible to define a distance function on that satisfies the triangle inequality, and a measure , and from the measure we can define integrals. Taking partial derivatives is still a bit tricky, and we will return to it when we talk about the gradient.
, and so on. Then, for every small interval around a point we have an -dimensional coordinate system, which we can think of as an approximation of the interval around as a piece of ; these coordinate systems are called “charts” and their collection is called an “atlas.” Charts of nearby points are supposed to be “consistent in their intersection,” which is assured by consistent mappings between them. For every point we also have an -dimensional vector space, which is the tangent space at . There are also mapping that relate the tangent spaces of nearby points. Finally, we have a “metric,” that, to make things more confusing, is not a distance function that satisfies the triangle inequality, but is the definition of an inner product between vectors of the tangent spaces. From the metric, it is possible to define a distance function on that satisfies the triangle inequality, and a measure , and from the measure we can define integrals. Taking partial derivatives is still a bit tricky, and we will return to it when we talk about the gradient.
If  is a subset of the manifold, then the boundary
is a subset of the manifold, then the boundary 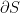 of is the set of points such that there are arbitrarily small intervals around that contain both elements of and elements of
of is the set of points such that there are arbitrarily small intervals around that contain both elements of and elements of  . For nice enough , will be an -dimensional object, so we will have
. For nice enough , will be an -dimensional object, so we will have 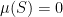 , but we can use the metric to define an -dimensional measure .
, but we can use the metric to define an -dimensional measure .
So we have a general sense of the definition of the Cheeger constant in manifold. For the analogy to graphs, we should think of the points of as  , of as
, of as 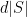 , of infinitesimally close points
, of infinitesimally close points  as an edge, and of the boundary of a set as the set of edges leaving .
as an edge, and of the boundary of a set as the set of edges leaving .
1.2. What is the Laplacian?
Now we have to define the Laplacian. The Laplacian is a linear operator that maps a function to a function  , and it is defined as
, and it is defined as

where 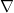 is the gradient operator and
is the gradient operator and  is the divergence operator. (All the functions that we talk about are infinitely differentiable.)
is the divergence operator. (All the functions that we talk about are infinitely differentiable.)
To see what these operators are, and what they have to do with the Laplacian of graphs, recall that, in a graph,
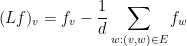
the Laplacian of  at
at  is the difference between the value of
is the difference between the value of  at and the average value of at neighbors of . Similarly, in a manifold,
at and the average value of at neighbors of . Similarly, in a manifold,  measures how much bigger
measures how much bigger 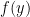 tends to be on average than
tends to be on average than  at a random point close to .
at a random point close to .
We will give some intuition about how the definition of the Laplacian in matches the intuition from the case of graphs. The generalization from to an -dimensional manifold is quite technical, but the general intuition is similar.
1.3. The Laplacian in one dimension
To see how to formalize this intuition, suppose 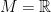 and so
and so  . Then, our intuition for the Laplacian of at is that, for a small
. Then, our intuition for the Laplacian of at is that, for a small  , we should look at
, we should look at
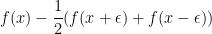
Qualitatively, this quantity is positive if is concave and negative if is convex, so it seems related to  , where
, where 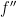 is the second derivative of . Indeed, the Taylor expansion of at is
is the second derivative of . Indeed, the Taylor expansion of at is
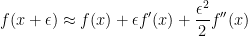
and so

And, indeed, for functions both the gradient operator and the divergence operator are just the derivative operator, and so 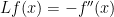 and we have
and we have

which matches our intuition from the case of graphs.
For functions , the operator is linear, and we may ask if it has eigenvalues and eigenfunctions, that is, if there are numbers  and functions for which the equation
and functions for which the equation

holds. Let’s see: what functions are equal to their second derivative, up to a multiplicative constant? For example,  and
and  are, where
are, where  is an integer. (So is
is an integer. (So is  .)
.)
Now suppose that our manifold is a unit circle in the plane, that is, points of are of the form  . This is a (one-dimensional) manifold because a small arc around a point is quite close to being a straight segment. If is periodic with period
. This is a (one-dimensional) manifold because a small arc around a point is quite close to being a straight segment. If is periodic with period ![{[0,2\pi]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C2%5Cpi%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , we can use it to define a function
, we can use it to define a function  on , where
on , where  ; similarly, if
; similarly, if  is defined on the circle we can think of it as a periodic function with period , where
is defined on the circle we can think of it as a periodic function with period , where 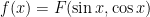 . In fact, there isn’t really any difference between thinking of functions defined over and periodic functions of period , and the Laplacian of will be the operator that takes a periodic function to minus its second derivative. So and will be eigenvectors of the Laplacian of the circle, with eigenvalues
. In fact, there isn’t really any difference between thinking of functions defined over and periodic functions of period , and the Laplacian of will be the operator that takes a periodic function to minus its second derivative. So and will be eigenvectors of the Laplacian of the circle, with eigenvalues  . Note the extreme similarity to the spectrum of the circle as a graph, where the eigenvectors are vectors whose
. Note the extreme similarity to the spectrum of the circle as a graph, where the eigenvectors are vectors whose  -th coordinate is
-th coordinate is  or
or 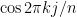 and
and 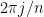 ranges in . The main difference is one of normalization: in the circle graph, all eigenvalues are at most 2, at the smallest positive one is about
ranges in . The main difference is one of normalization: in the circle graph, all eigenvalues are at most 2, at the smallest positive one is about 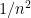 ; in the circle manifold the eigenvalues are arbitrarily large, and the smallest positive one is 1. However, if we call
; in the circle manifold the eigenvalues are arbitrarily large, and the smallest positive one is 1. However, if we call  the -th smallest eigenvalue, in both cases we have that
the -th smallest eigenvalue, in both cases we have that  is about
is about 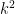 .
.
1.4. The gradient in
For the higher-dimensional case, let us start from the case  . In this case, let us fix the orthonormal basis
. In this case, let us fix the orthonormal basis  for where
for where  is the vector that has zeroes everywhere except a 1 in the
is the vector that has zeroes everywhere except a 1 in the  -th position. For a function
-th position. For a function 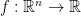 , its gradient
, its gradient 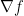 is a function that maps a point
is a function that maps a point  to an -dimensional vector, which contains the partial derivatives of , that is
to an -dimensional vector, which contains the partial derivatives of , that is

where, for a vector 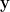 , the partial derivative
, the partial derivative  is the function
is the function

If and  are orthogonal then
are orthogonal then

this means that for every vector  we have
we have
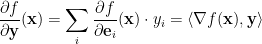
It is important to note that there was nothing special about the use of the base  . Take an arbitrary orthonormal base
. Take an arbitrary orthonormal base  , then define the “base-
, then define the “base-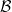 ” gradient as
” gradient as
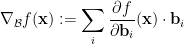
then we again have that for every , after writing  ,
,
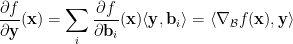
so, in fact,  is always the same vector
is always the same vector  regardless of the choice of .
regardless of the choice of .
Indeed, we could take as the definition of the gradient to say that is the unique vector that satisfies the equation

for every .
It is also worth nothing that, among all unit vectors , the one that maximizes  is the one parallel to , so points in the direction in which grows the most near , which is the most intuitive interpretation.
is the one parallel to , so points in the direction in which grows the most near , which is the most intuitive interpretation.
If in general, then  is a vector in the tangent space of at , and the directional derivative
is a vector in the tangent space of at , and the directional derivative  , where is a vector in the tangent space at , satisfies
, where is a vector in the tangent space at , satisfies

where the inner product is in the tangent space. The definition of partial derivative, and the fact that there is a vector that satisfies the above equation for every is beyond the scope of these notes.
1.5. The divergence in
The definition of divergence is a bit more tricky. If 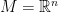 , then takes in input a function
, then takes in input a function  , and returns a function
, and returns a function  . The definition of
. The definition of  , (up to scaling) can be thought of as follows: consider a small sphere of radius around , pick a random element of the sphere by picking a random unit vector and considering the vector
, (up to scaling) can be thought of as follows: consider a small sphere of radius around , pick a random element of the sphere by picking a random unit vector and considering the vector 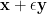 , and then look at the average value of
, and then look at the average value of

which is the component of  that “points away” from in the direction of the line that joins to
that “points away” from in the direction of the line that joins to  .
.
This will be positive if the vector  tends to point away from , for random close to , and negative otherwise.
tends to point away from , for random close to , and negative otherwise.
1.6. The Laplacian in
Now let us see what happens when we instantiate this definition to 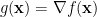 . We pick a random unit vector , and we compute
. We pick a random unit vector , and we compute

For small ,

so

which is the average rate of growth of in a random direction. So we have that 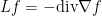 is the rate of decrease of in a random direction. This is roughly the equivalent of the discrete case where
is the rate of decrease of in a random direction. This is roughly the equivalent of the discrete case where 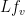 is the difference between
is the difference between  and the average value of
and the average value of  for a random neighbor
for a random neighbor  of .
of .
It turns out that we can also make the correspondence between the discrete and the continuous case closer, by finding linear operators in the discrete case whose composition gives the Laplacian, and that are somewhat analogous to and  .
.
Consider the  incidence matrix
incidence matrix  of defined as follows:
of defined as follows:

where we have fixed an arbitrary orientation of the edges of  . Then
. Then  is an
is an 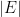 -dimensional vector such that
-dimensional vector such that  equals
equals 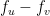 for every (directed) edge
for every (directed) edge  . We can also think of as mapping a vertex
. We can also think of as mapping a vertex  to a
to a  -dimensional vector
-dimensional vector  , whose -th coordinate is
, whose -th coordinate is  where
where 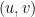 is the -th outgoing edge from . In this view, acts somewhat like the
is the -th outgoing edge from . In this view, acts somewhat like the  , giving us all the “derivatives” of
, giving us all the “derivatives” of  in all directions. (The minus sign is because in the derivative at we consider
in all directions. (The minus sign is because in the derivative at we consider 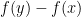 where is close to , but “at ” gives us .)
where is close to , but “at ” gives us .)
If is an -dimensional vector, then

is the flow through , if we think of as defining a flow on the (directed) edges of . This is the analog of the divergence  , which also computes the net flow of away from a point .
, which also computes the net flow of away from a point .
The reader can verify that we indeed have 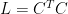 .
.


Amazing post! (a small typo: there’s a limit with epsilon tending to infty instead of 0)
awesoem post, thanks
Pingback: Buser Inequalities in Graphs | in theory