Several results in additive combinatorics have the flavor of decomposition results in which one shows that an arbitrary combinatorial object can be approximated by a “sum” of a “low complexity” part and a “pseudorandom” part. This is helpful because it reduces the task of proving that an arbitrary object has a certain property to the easier task of proving that low-complexity objects and pseudorandom objects have the property. (Provided that the property is preserved by the approximation and the sum.)
Many examples of such results are given in the paper accompanying Terry Tao’s tutorial at FOCS’07.
Usually, one needs a strong notion of approximation, and in such cases the complexity of the “low complexity” part is fantastically large (a tower of exponentials in the approximation parameter), as in the Szemeredi Regularity Lemma, which can be seen as a prototypical such “decomposition” result. In some cases, however, weaker notions of approximation are still useful, and one can have more reasonable complexity parameters, as in the Weak Regularity Lemma of Frieze and Kannan.
A toy example of a “weak decomposition result” is the following observation: let  be the linear functions
be the linear functions  used as the basis for Fourier analysis of functions
used as the basis for Fourier analysis of functions  , let
, let ![g: {\mathbb F}_2^n \rightarrow [-1,1]](https://s0.wp.com/latex.php?latex=g%3A++%7B%5Cmathbb+F%7D_2%5En+%5Crightarrow+%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) be a bounded function, and consider its Fourier transform
be a bounded function, and consider its Fourier transform

Then we can write

where
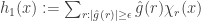
is the truncation of the Fourier expansion containing only the larger coefficient, and  . Since we know
. Since we know 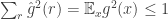 , we can see that
, we can see that 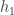 is defined as a linear combination of at most
is defined as a linear combination of at most  functions
functions  , and so it has “low complexity” relative to the linear functions.
, and so it has “low complexity” relative to the linear functions.
The other observation is that, for every function , we have

So we have written  as a sum of a function of “complexity”
as a sum of a function of “complexity”  and of a “pseudorandom” function all whose Fourier coefficients are small. The reason we think of a function with small Fourier coefficients as “pseudorandom” is because (the uniform distribution over) a set is
and of a “pseudorandom” function all whose Fourier coefficients are small. The reason we think of a function with small Fourier coefficients as “pseudorandom” is because (the uniform distribution over) a set is  -biased (in the Naor-Naor sense) if and only if its indicator function has small Fourier coefficients. Another way to look at the decomposition is to see that we have found a function that has “small complexity” relative to the set of Fourier basis functions , and such that and are indistinguishable by basis functions, that is,
-biased (in the Naor-Naor sense) if and only if its indicator function has small Fourier coefficients. Another way to look at the decomposition is to see that we have found a function that has “small complexity” relative to the set of Fourier basis functions , and such that and are indistinguishable by basis functions, that is,

These are trivial observation, and they seem to depend essentially on the fact that the are orthogonal. Indeed, this is not the case.
By modifying the main idea in the Frieze-Kannan paper, it is possible to prove the following result.
Theorem 1 (Low Complexity Approximation, Simple Version) Let  be a probability space,
be a probability space, ![g:X \rightarrow [-1,1]](https://s0.wp.com/latex.php?latex=g%3AX+%5Crightarrow+%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) a bounded function,
a bounded function,  a collection of bounded functions
a collection of bounded functions ![f:X \rightarrow [-1,1]](https://s0.wp.com/latex.php?latex=f%3AX+%5Crightarrow+%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) , and an approximation parameter.
, and an approximation parameter.
Then there is a function 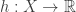 such that
such that
We can see that the Fourier analysis approximation we discussed above is the special case in which is the set of linear functions.
The proof is surprisingly simple. Assume without loss of generality that is “closed under negation,” that is, if 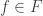 then
then 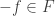 . (Otherwise we apply the following argument to the closure of .) We construct the function
. (Otherwise we apply the following argument to the closure of .) We construct the function  via the following algorithm.
via the following algorithm.
If the algorithm terminates after a finite number  of steps, then the function
of steps, then the function 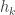 is indistinguishable as required, and we have
is indistinguishable as required, and we have  , so we just need to argue that the algorithm always terminates, and it does so within
, so we just need to argue that the algorithm always terminates, and it does so within 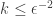 steps.
steps.
We prove this via an energy decreasing argument. Consider the error at time  ,
,  , and define the “energy” at time to be
, and define the “energy” at time to be  . At time zero,
. At time zero,  . It remains to show that the energy decreases by at least
. It remains to show that the energy decreases by at least  at every step. (The energy is always non-negative, so if it starts at 1 and it decreases by at least at every step, there can be no more than
at every step. (The energy is always non-negative, so if it starts at 1 and it decreases by at least at every step, there can be no more than  steps.)
steps.)
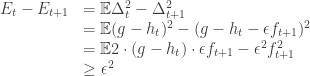
To see how Theorem 1 relates to the regularity lemma on graphs, let  be the set of edges in the complete graph
be the set of edges in the complete graph 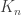 over
over  vertices, and let
vertices, and let  be an arbitrary graph over vertices, which we shall think of as a function
be an arbitrary graph over vertices, which we shall think of as a function 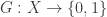 . For two disjoint sets of vertices
. For two disjoint sets of vertices 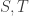 , let
, let  be the indicator function of the set of edges with one endpoint in
be the indicator function of the set of edges with one endpoint in  and one endpoint in
and one endpoint in  , let be the set of such functions, and let
, let be the set of such functions, and let  be the uniform distribution over . Then, for every , Theorem 1 gives us an approximating weighted graph
be the uniform distribution over . Then, for every , Theorem 1 gives us an approximating weighted graph  such that
such that
-
 is a weighted sum of
is a weighted sum of  functions
functions 
- For every two sets of vertices , the number of edges in between and differs from the (weighted) number of edges in between and by at most
 . (Indeed, at most
. (Indeed, at most  .)
.)
The model graph is helpful because one can solve several optimization problems on it (such as Max Cut) in time dependent only on , and then transfer such solutions to , paying an additive cost of (which is negligible if is dense).
Regularity Lemmas, however, are usually stated in terms of partitions of the sets of vertices, not in terms of linear combinations. Also, it is somewhat undesirable that the approximating graph has weights that are not guaranteed to be bounded. Analogously, in Theorem 1, it would be desirable for to be bounded, which is not guaranteed by the construction. (Although one can see that  , the best bound we can give about individual inputs is
, the best bound we can give about individual inputs is 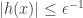 .)
.)
To deal with this issue, we first need a couple of definitions.
If 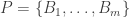 is a partition of , and
is a partition of , and 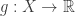 is any function, then the conditional expectation of on
is any function, then the conditional expectation of on  is the function
is the function  defined as
defined as
![g_P (x) := {\mathbb E} [ g_P(y) | \ y\in B_i : x \in B_i ]](https://s0.wp.com/latex.php?latex=g_P+%28x%29+%3A%3D+%7B%5Cmathbb+E%7D+%5B+g_P%28y%29+%7C+%5C+y%5Cin+B_i+%3A+x+%5Cin+B_i+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
that is, on input  , belonging to block
, belonging to block 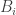 of the partition , the value of
of the partition , the value of 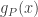 is the expectation of on the block . To visualize this definition, suppose that elements of are people, are countries, and
is the expectation of on the block . To visualize this definition, suppose that elements of are people, are countries, and 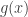 is the wealth of person . Now, spread around the wealth evenly within each country; then
is the wealth of person . Now, spread around the wealth evenly within each country; then  is the post-spreading-around wealth of .
is the post-spreading-around wealth of .
The following definition will simplify some discussions on indistinguishability: if is a probability space, is a collection of functions 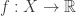 and is any function, then
and is any function, then
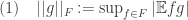
Note that this is indeed a norm, and that and are -indistinguishable by if and only if 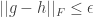 .
.
Given these definitions, Frieze and Kannan prove that, in the special case in which are edges of a complete graph and is the collection of indicator functions of cuts, if is a partition of defined by first picking functions  and then creating the coarsest partition such that every function
and then creating the coarsest partition such that every function  is constant on each block of the partition (we call the partition generated by
is constant on each block of the partition (we call the partition generated by  ), and if is any function and is a function which is constant on each block of
), and if is any function and is a function which is constant on each block of  , then
, then

From this, we have that if 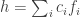 is the function of Theorem 1, and is the partition defined by the , then
is the function of Theorem 1, and is the partition defined by the , then

And so the function 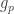 is also a good approximation for . Nicely, is precisely the type of approximation described in the standard regularity lemma, and all its edge weights are between 0 and 1. I don’t know how to prove (2) in general, but the iterative partitioning proof of the Weak Regularity Lemma can be abstracted into the following result.
is also a good approximation for . Nicely, is precisely the type of approximation described in the standard regularity lemma, and all its edge weights are between 0 and 1. I don’t know how to prove (2) in general, but the iterative partitioning proof of the Weak Regularity Lemma can be abstracted into the following result.
Theorem 2 (Low Complexity Approximation, Partition Version) Let be a probability space, a bounded function, a collection of boolean functions  , and an approximation parameter.
, and an approximation parameter.
Then there is a function ![h: X \rightarrow [-1,1]](https://s0.wp.com/latex.php?latex=h%3A+X+%5Crightarrow+%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) such that
such that
The proof proceeds by starting with being the trivial partition containing only one block; we continue until we have a partition such that 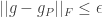 . If the current partition is such that
. If the current partition is such that  then we add the function such that
then we add the function such that 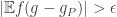 to the collection of functions used to define . Every time we thus refine , we can show that
to the collection of functions used to define . Every time we thus refine , we can show that  increases by
increases by  , and it is always at most one, so we are able to bound the number of steps.
, and it is always at most one, so we are able to bound the number of steps.
Note that, in Theorems 1 and 2, we do not need to be finite; indeed, can be any measure space such that 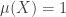 , provided we interpret the notation
, provided we interpret the notation 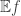 to mean
to mean  . (In such cases, we shall also need to make proper integrability assumptions on and the functions in .) From Theorems 1 and 2 we can reconstruct the “Analytic Weak Regularity Lemmas” of Lovasz and Szegedy. For example, if
. (In such cases, we shall also need to make proper integrability assumptions on and the functions in .) From Theorems 1 and 2 we can reconstruct the “Analytic Weak Regularity Lemmas” of Lovasz and Szegedy. For example, if ![X = [0,1]^2](https://s0.wp.com/latex.php?latex=X+%3D+%5B0%2C1%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002) , and is the class of functions of the form
, and is the class of functions of the form  , over all measurable sets , then the norm
, over all measurable sets , then the norm  is the same as the norm
is the same as the norm  defined in Section 4 of the Lovasz-Szegedy paper, and their Lemma 7 follows from our Theorem 1.
defined in Section 4 of the Lovasz-Szegedy paper, and their Lemma 7 follows from our Theorem 1.
For a complexity-theoretic interpretation, note that, in Theorem 2, we can take to be the class of functions computable by circuits of size at most ; then the theorem gives us an approximating function which can be computed in size  .
.
Could we make the complexity of the approximation polynomial in  , while retaining the useful property that the approximating function is bounded? This is the subject of a new paper by Madhur Tulsiani, Salil Vadhan, and I, and also the subject of a forthcoming post.
, while retaining the useful property that the approximating function is bounded? This is the subject of a new paper by Madhur Tulsiani, Salil Vadhan, and I, and also the subject of a forthcoming post.

, and the coefficients
satisfy
;

0;
such that



functions
, where

Pingback: Boosting and the Regularity Lemma « in theory
Why the complexity of $h$ is Theorem 2 is $S.exp(O(\epsilon ^{-2})$ ?
I don’t see a way other than going over all X and computing all f’s to find out the partition the input is in, and then computing f over all of that domain and taking the average 😦