
The multiplicative weights algorithm is simple to define and analyze, and it has several applications, but both its definition and its analysis seem to come out of nowhere. We mentioned that all the quantities arising in the algorithm and its analysis have statistical physics interpretations, but even this observation brings up more questions than it answers. The Gibbs distribution, for example, does put more weight on lower-energy states, and so it makes sense in an optimization setting, but to get good approximations one wants to use lower temperatures, while the distributions used by the multiplicative weights algorithms have temperature 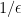
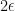
Furthermore, it is not clear how we would generalize the ideas of multiplicative weights to the case in which the set of feasible solutions 
Today we discuss the “Follow the Regularized Leader” method, which provides a framework to design and analyze online algorithms in a versatile and well-motivated way. We will then see how we can “discover” the definition and analysis of multiplicative weights, and how to “discover” another online algorithm which can be seen as a generalization of projected gradient descent (that is, one can derive the projected gradient descent algorithm and its analysis from this other online algorithm).
1. Follow The Regularized Leader
We will first state some results in full generality, making no assumptions on the set 
Let us try to define an online optimization algorithm from scratch. The solution 

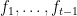

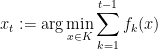
to be the best solution for the previous steps. (Note that the algorithm does not prescribe what solution to use at step 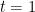
It is possible for FTL to perform very badly. Consider for example the “experts” setting in which we analyzed multiplicative weights: the set of feasible solutions 
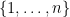
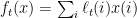



-
,
-
,
-
,
-
,
-
,
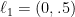





In which, after 


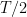


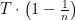
In the above bad example, the algorithm keeps “overfitting” to the past history: if an expert is a bit better than the others, the algorithm puts all its probability mass on that expert, and the algorithm keeps changing its mind at every step. Interestingly, this is the only failure mode of the algorithm.
Theorem 1 (Analysis of FTL) For any sequence of cost functions
and any number of time steps

So that if the functions 

Proof: Recalling the definition of regret,

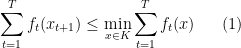
We will prove (1) by induction. The base case 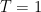
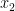

where the middle step follows from the use of the inductive assumption, which gives


The above example and analysis suggest that we should modify FTL in such a way that the choices of the algorithm don’t change too much from step to step, and that the solution
In order to do this, we introduce a new function 

This algorithm is called Follow the Regularized Leader or FTRL. Typically, the function 
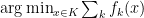
We have the following analysis that makes no assumptions on
Theorem 2 (Analysis of FTRL) For every sequence of cost functions and every regularizer function, the regret after
where
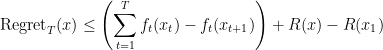

Proof: Let us run for 
Now consider the following mental experiment: we run the FTL algorithm for 



Having established these results, the general recipe to solve an online optimization problem will be to find a regularizer function 



2. Negative-Entropy Regularization
Let us consider again the “experts” setting, that is, the online optimization setup in which 
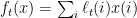
The example we showed above showed that FTL will tend to put all the probability mass on one expert. We would like to choose a regularizer that fights this tendency by penalizing “concentrated” distributions and favoring “spread-out” distributions. This observation might trigger the thought that the entropy of a distribution is a good measure of how concentrated or spread out it is, although the entropy is actually higher for spread-out distribution and smaller for concentrated ones. So we will use as a regularizer minus the entropy, multiplied by an appropriate scaling factor:

(Entropy is usually defined using logarithms in base 2, but using natural logarithms will make it cleaner to take derivatives, and it only affects the constant factor 
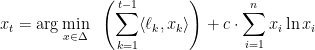
To compute the minimum of the above function we will use the method of Lagrange multipliers. Specialized to our setting, the method of Lagrange multiplier states that if we want to solve the constrained minimization problem

we introduce a new parameter 

Then it is possible to prove that if 



Ignoring for a moment the non-negativity constraints, the constraint 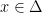


The partial derivative of the above expression with respect to 

If we want the gradient to be zero then we want all the above expressions to be zero, which translates to
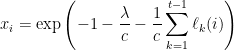
There is only one value of
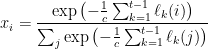
Notice that this is exactly the solution computed by the multiplicative weights algorithm, if we choose 
Now it remains to bound, at each time step,

For this, it is convenient to return to the notation that we used in describing the multiplicative weights algorithm, that is, it is convenient to work with the weights defined as
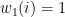

so that, at each time step
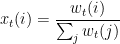
We are assuming 

For every 


and
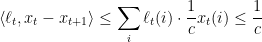
Putting it all together, we have

Choosing 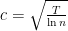

Thus, we have reconstructed the analysis of the multiplicative weights algorithm.
Interestingly, the analysis that we derived today is not exactly identical to the one from the post on multiplicative weights. There, we derived the bound

while here, setting 

where 
3. L2 Regularization
Now that we have a general method, let us apply it to a new context: suppose that, as before, our cost functions are linear, but let 

What regularizer should we use? In reasoning about regularizers, it can be helpful to think about what would go wrong if we use FTL, and then considering what regularizer would successfully “pull away” from the bad solutions found by FTL. In this context of linear loss functions and unbounded solutions, FTL will pick an infinitely big solution at each step, or, to be more precise, the “max” in the definition of FTL is undefined. To fight this tendency of FTL to go off to infinity, it makes sense for the regularizer to be a measure of how big a solution is. Since we are going to have to compute derivatives, it is good to use a measure of “bigness” with a nice gradient, and 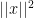
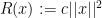
This tells us that
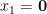
and

The function that we are minimizing in the above expression is convex, so we just have to compute the gradient and set it to zero
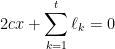
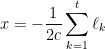
Which can be also expressed as

This makes perfect sense because, in the “experts” interpretation, we want to penalize the experts that performed badly in the past. Here we have no constraints on our allocations, so we simply decrease (additively this time, not multiplicatively) the allocation to the experts that caused a higher loss.
To compute the regret bound, we have

and so the regret with respect to a solution


If we know a bound


then we can optimize 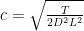
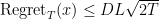
3.1. Dealing with Constraints
Consider now the case in which the loss functions are linear and 


How can we solve the above constrained optimization problem? A very helpful observation is that we can first solve the unconstrained optimization and then project on
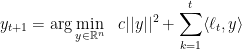
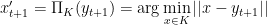
and we claim that we always have 

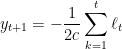
Now the definition of 






In order to bound the regret, we have to compute

and since L2 projections cannot increase L2 distances, we have
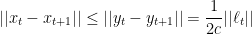
So the regret bound is
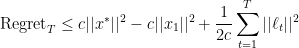
If 




which can be optimized to
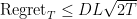
3.2. Deriving the Analysis of Gradient Descent
Suppose that 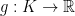
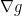

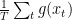
Unfortunately, this is not a very helpful idea, because if we ran an FTRL algorithm against an adversary that keeps proposing

which, for large
Indeed, the power of the FTRL algorithm is that the algorithm does well even though it does not know the cost function, and if we keep using the same cost function at each step we are not making a good use of its power. Now, suppose that we use cost functions 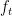

Then, after

meaning
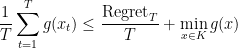
and so one of the

and so the average of the
How do we find cost functions that satisfy the above two properties and for which the FTRL algorithm is easy to implement? The idea is to let
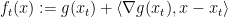
The 

is a consequence of the convexity of
The cost functions that we have defined are affine functions, that is, each of them equals a constant plus a linear function

Adding a constant term to a cost function does not change the iteration of FTRL, and does not change the regret (because the same term is added both to the solution found by the algorithm and to the offline optimum), so the algorithm is just initialized with


and then continues with the update rules
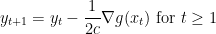

which is just projected gradient descent.
If we have known upper bounds

and

then we have
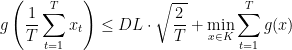
which means that to achieve additive error 


Hi Luca, I think there’s a typo in “Negative Entropy Regularization” section. When you say:
“With this choice of regularizer, we have: $$ x_t = \argmin_{x \in Delta} \sum_{k=1}^{t-1} \langle \ell_k, x_k \rangle + … $$ ”
But the $k$ subscript shouldn’t be there for the x in the inner product, right? And also later, same thing: “the constraint {x \in \Delta} reduces to {\sum_i x_i = 1}, so we have to consider the function
$$ \left( \sum_{k=1}^{t-1} \langle \ell_k , x_k \rangle \right ) + … $$ “
Thanks for the posts, very educational and cool. You write great motivated math.
Pingback: Online Optimization Post 7: Matrix Multiplicative Weights Update | in theory