
Scribed by Jonah Sherman
Summary
Today we prove the Goldreich-Levin theorem.
1. Goldreich-Levin Theorem
We use the notation

Theorem 1 (Goldreich and Levin) Let
be a permutation computable in time
. Suppose that
is an algorithm of complexity
such that
Then there is an algorithm
of complexity at most
such that
![\displaystyle \mathop{\mathbb P}_{x,r} [ A(f(x),r) = \langle x,r \rangle ] \geq \frac 12 + \epsilon \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D_%7Bx%2Cr%7D+%5B+A%28f%28x%29%2Cr%29+%3D+%5Clangle+x%2Cr+%5Crangle+%5D+%5Cgeq+%5Cfrac+12+%2B+%5Cepsilon+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \mathop{\mathbb P}_{x} [ A'(f(x)) = x ] \geq \frac \epsilon 4](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D_%7Bx%7D+%5B+A%27%28f%28x%29%29+%3D+x+%5D+%5Cgeq+%5Cfrac+%5Cepsilon+4+&bg=ffffff&fg=000000&s=0&c=20201002)
Last time we proved the following partial result.
Lemma 2 (Goldreich-Levin Algorithm — Weak Version) Suppose we have access to a function
such that, for some unknown
, we have
where
is an unknown string.
Then there is an algorithm GLW that runs in time
and makes
oracle queries into
and, with probability at least
, outputs
![\displaystyle \mathop{\mathbb P}_{r \in \{ 0,1 \}^n} [ H(r) = \langle x,r \rangle ] \geq \frac 78 \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cmathop%7B%5Cmathbb+P%7D_%7Br+%5Cin+%5C%7B+0%2C1+%5C%7D%5En%7D+%5B+H%28r%29+%3D+%5Clangle+x%2Cr+%5Crangle+%5D+%5Cgeq+%5Cfrac+78+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
This gave us a proof of a variant of the Goldreich-Levin Theorem in which the right-hand-side in (2) was 

We need, however, the full Goldreich-Levin Theorem in order to construct a pseudorandom generator, and so it seems that we have to prove a strengthening of Lemma 2 in which the right-hand-side in (4) is 
Unfortunately such a stronger version of Lemma 2 is just false: for any two different 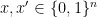
![\displaystyle \mathop{\mathbb P}_{r\sim \{ 0,1 \}^n} [ H(r) = \langle x,r \rangle ] = \frac 34](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D_%7Br%5Csim+%5C%7B+0%2C1+%5C%7D%5En%7D+%5B+H%28r%29+%3D+%5Clangle+x%2Cr+%5Crangle+%5D+%3D+%5Cfrac+34+&bg=ffffff&fg=000000&s=0&c=20201002)
and
![\displaystyle \mathop{\mathbb P} _{r\sim \{ 0,1 \}^n} [ H(r) = \langle x',r \rangle ] = \frac 34](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D+_%7Br%5Csim+%5C%7B+0%2C1+%5C%7D%5En%7D+%5B+H%28r%29+%3D+%5Clangle+x%27%2Cr+%5Crangle+%5D+%3D+%5Cfrac+34+&bg=ffffff&fg=000000&s=0&c=20201002)
so no algorithm can be guaranteed to find ![{\mathop{\mathbb P} [ H(r) = \langle x,r \rangle ] = \frac 34}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+P%7D+%5B+H%28r%29+%3D+%5Clangle+x%2Cr+%5Crangle+%5D+%3D+%5Cfrac+34%7D&bg=ffffff&fg=000000&s=0&c=20201002)
We can, however, prove the following:
Lemma 3 (Goldreich-Levin Algorithm) Suppose we have access to a function
where
is given.
Then there is an algorithm
that runs in time
, makes
oracle queries into
such that
and with probability at least
,
.
![\displaystyle \mathop{\mathbb P}_{r \in \{ 0,1 \}^n} [ H(r) = \langle x,r \rangle ] \geq \frac 12 + \epsilon \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cmathop%7B%5Cmathbb+P%7D_%7Br+%5Cin+%5C%7B+0%2C1+%5C%7D%5En%7D+%5B+H%28r%29+%3D+%5Clangle+x%2Cr+%5Crangle+%5D+%5Cgeq+%5Cfrac+12+%2B+%5Cepsilon+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)
The Goldreich-Levin algorithm
The Goldreich-Levin Theorem is an easy consequence of Lemma 3. Let 


From the assumption that
![\displaystyle \mathop{\mathbb P}_{x,r} [ A(f(x),r)= \langle x, r \rangle] \geq \frac 12 + \epsilon](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D_%7Bx%2Cr%7D+%5B+A%28f%28x%29%2Cr%29%3D+%5Clangle+x%2C+r+%5Crangle%5D+%5Cgeq+%5Cfrac+12+%2B+%5Cepsilon+&bg=ffffff&fg=000000&s=0&c=20201002)
it follows by Markov’s inequality (See Lemma 9 in the last lecture) that
![\displaystyle \mathop{\mathbb P}_x \left[ \mathop{\mathbb P}_r [A(f(x),r)=\langle x, r \rangle] \geq \frac 12 + \frac \epsilon 2 \right] \geq \frac \epsilon 2](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D_x+%5Cleft%5B+%5Cmathop%7B%5Cmathbb+P%7D_r+%5BA%28f%28x%29%2Cr%29%3D%5Clangle+x%2C+r+%5Crangle%5D+%5Cgeq+%5Cfrac+12+%2B+%5Cfrac+%5Cepsilon+2+%5Cright%5D+%5Cgeq+%5Cfrac+%5Cepsilon+2+&bg=ffffff&fg=000000&s=0&c=20201002)
Let us call an ![{\mathop{\mathbb P}_r [A(f(x),r)=\langle x, r \rangle] \geq \frac 12 + \frac \epsilon 2}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+P%7D_r+%5BA%28f%28x%29%2Cr%29%3D%5Clangle+x%2C+r+%5Crangle%5D+%5Cgeq+%5Cfrac+12+%2B+%5Cfrac+%5Cepsilon+2%7D&bg=ffffff&fg=000000&s=0&c=20201002)



2. The Goldreich-Levin Algorithm
In this section we prove Lemma 3.
We are given an oracle 


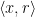
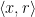
We first choose 

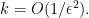

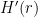

For each 

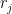

![\displaystyle \mathop{\mathbb P}_{r,r_1,\ldots,r_k}\left [H'(r) = \langle x, r \rangle \right ] \ge \frac{31}{32}. \ \ \ \ \ (6)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D_%7Br%2Cr_1%2C%5Cldots%2Cr_k%7D%5Cleft+%5BH%27%28r%29+%3D+%5Clangle+x%2C+r+%5Crangle+%5Cright+%5D+%5Cge+%5Cfrac%7B31%7D%7B32%7D.+%5C+%5C+%5C+%5C+%5C+%286%29&bg=ffffff&fg=000000&s=0&c=20201002)
from which it follows that
![\displaystyle \mathop{\mathbb P}_{r_1,\ldots,r_k}\left [ \mathop{\mathbb P}_r \left [H'(r) = \langle x, r \rangle \right ] \ge \frac 78 \right ] \ge \frac{3}{4}. \ \ \ \ \ (7)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D_%7Br_1%2C%5Cldots%2Cr_k%7D%5Cleft+%5B+%5Cmathop%7B%5Cmathbb+P%7D_r+%5Cleft+%5BH%27%28r%29+%3D+%5Clangle+x%2C+r+%5Crangle+%5Cright+%5D+%5Cge+%5Cfrac+78+%5Cright+%5D+%5Cge+%5Cfrac%7B3%7D%7B4%7D.+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0&c=20201002)
Consider the following algorithm.
- Algorithm GL-First-Attempt
- pick
where
- for all
- define
as majority of:
- apply Algorithm GLW to
- add result to list
- define
- return list
- pick


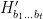
The idea behind this program is that we do not in fact know the values 

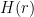
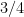
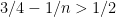
The obvious problem with this algorithm is that its running time is exponential in 

To overcome these problems, consider the following similar algorithm.
- Algorithm GL
- pick
where
- define
for each non-empty
- for all
- define
for each non-empty
- define
over non-empty
- apply Algorithm GLW to
- add result to list
- define
- return list
- pick



Let us now see why this algorithm works. First we define, for any nonempty 

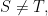






for every non-empty 

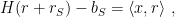
and these events are pair-wise independent. Note the following simple lemma.
Lemma 4 Let
be a set of pairwise independent
random variables, each of which is
with probability at least
Then
.
Proof: Let 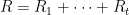
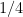
![{{\bf Var}[R] = {\bf Var} [ R_1+\ldots+R_k] = \sum_i {\bf Var}[R_k] \leq k/4}](https://s0.wp.com/latex.php?latex=%7B%7B%5Cbf+Var%7D%5BR%5D+%3D+%7B%5Cbf+Var%7D+%5B+R_1%2B%5Cldots%2BR_k%5D+%3D+%5Csum_i+%7B%5Cbf+Var%7D%5BR_k%5D+%5Cleq+k%2F4%7D&bg=ffffff&fg=000000&s=0&c=20201002)
We then have
![\displaystyle \mathop{\mathbb P}[ R \leq k/2] \leq \mathop{\mathbb P}[ |R - \mathop{\mathbb E}[R]| \geq \epsilon k] \leq \frac{{\bf Var}[R]}{\epsilon^2 k^2} \leq \frac 1 {4\epsilon^2 k}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D%5B+R+%5Cleq+k%2F2%5D+%5Cleq+%5Cmathop%7B%5Cmathbb+P%7D%5B+%7CR+-+%5Cmathop%7B%5Cmathbb+E%7D%5BR%5D%7C+%5Cgeq+%5Cepsilon+k%5D+%5Cleq+%5Cfrac%7B%7B%5Cbf+Var%7D%5BR%5D%7D%7B%5Cepsilon%5E2+k%5E2%7D+%5Cleq+%5Cfrac+1+%7B4%5Cepsilon%5E2+k%7D+&bg=ffffff&fg=000000&s=0&c=20201002)

Lemma 4 allows us to upper-bound the probability that the majority operation used to compute 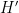




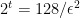




Pingback: Best query complexity of Goldreich-Levin / Kushilevitz-Mansour learning algorithm | MoVn - Linux Ubuntu Center
I did not read this text carefully
(since I’m currently preoccupied with something else),
but it seems to me that valuable info may be provided in
Section 2.5.2.4 of Vol 1 of my FoC book (*);
see Prop 2.5.4, and Footnotes 10 and 11…
Oded
*) http://www.wisdom.weizmann.ac.il/~oded/foc-vol1.html