
In which we show how to use expert advice, and introduce the powerful “multiplicative weight” algorithm.
We study the following online problem. We have 

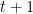
We want to come up with an algorithm to use the expert advice such that, at the end, that is, at time 
The “multiplicative update” algorithm provides a very good solution to this problem, and the analysis of this algorithm is a model for the several other applications of this algorithm, in rather different contexts.
1. A Simplified Setting
We begin with the following simplified setting: at each time step, we have to make a prediction about an event that has two possible outcomes, and we can use the advice of
The algorithm works as follows: at each step 


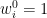
We now formalize the above algorithm in pseudocode. We use 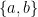
- for each
do
- for each time
- let
- if the sum of
over all the experts
is
, then predict
- else predict
- wait until the outcome is revealed
- for each
- if
- if
- let






To analyze the algorithm, let 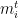
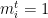
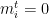


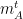
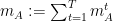
We make the following two observations:
- If the algorithm makes a mistake at time
, and, at the following step, the weight of those experts is divided by two, and this means that, if we make a mistake at time
Because the initial total weight is
, we have that, at the end,
- For each expert
, and, clearly,
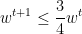


Together, the two previous observations mean that, for every expert
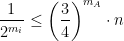
which means that, for every expert
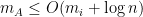
That is, the number of mistakes made by the algorithm is at most a constant times the number of mistakes of the best expert, plus an extra 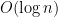
We will now discuss an algorithm that improves the above result in two ways. We will show that, for every 
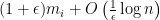
2. The General Result
We now consider the following model. At each time step 
![{m_i^t \in [-1,1]}](https://s0.wp.com/latex.php?latex=%7Bm_i%5Et+%5Cin+%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

As before, our algorithm maintains a weight for each expert, corresponding to our confidence in the expert. The weights are initialized to 1. When an expert causes a loss, we reduce his weight, and when an expert causes a gain, we increase his weight. To express the weight updated in a single instruction, we have 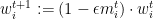
- for each
- for each time
- let
- let
- for each
- wait until the outcome is revealed
- let
be the loss of the strategy of expert
- for each
-
- let
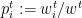

To analyze the algorithm, we will need the following technical result.
Fact 1 For every
,

Proof: We will use the Taylor expansion
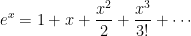
- The upper bound. The Taylor expansion above can be seen as
, that is,
equals
plus a sum of terms that are all non-negative when
. Thus, in particular, we have
for
- The lower bound for positive
, we have
and so, for
we have
- The lower bound for negative
we have
and so, for
we have

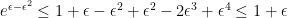

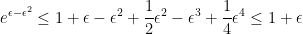

Now the analysis proceeds very similarly to the analysis in the previous section. We let

be the loss of the algorithm at time 

If we look at the total weight at time

and we can rewrite it as

Recalling that, initially,

For each expert
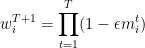
and, as before, we note that for every expert

Putting everything together, for every expert

Now it is just a matter of taking logarithms and of using the inequality that we proved before.


and, overall,

In the model of the previous section, at every step the loss of each expert is either 0 or 1, and so the above expression simplifies to
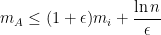
which shows that we can get arbitrarily close to the best expert.
In every case, (1) simplifies to
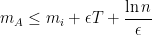
and, if we choose 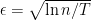

which means that we come close to the optimum up to a small additive error.
To see that this is essentially the best that we can hope for, consider a playing a fair roulette game as follows: for 



3. Applications
The general expert setting is very similar to a model of investments in which the experts correspond to stocks (or other investment vehicles) and the outcomes correspond to the variation in value of the stocks. The difference is that in our model we “invest” one unit of money at each step regardless of what happened in previous steps, while in investment strategies we compound our gains (and losses). If we look at the logarithm of the value of our investment, however, it is modeled correctly by the experts setting.
The multiplicative update algorithm that we described in the previous section arises in several other contexts, with a similar, or even identical, analysis. For example, it arises in the context of boosting in machine learning, and it leads to efficient approximate algorithms for certain special cases of linear programming.

Very interesting article. As a logician I’m particularly interested in the case when T=infinity. In particular, I’m interested in the case when the “experts” are really expert trolls and are intentionally trying to confuse us. For example, say that, in addition to trying to determine whether it will rain tomorrow, we also have a “secondary mission” which is to determine which expert is the most reliable. For simplicity, assume there are only two experts, A and B, both who have perfect knowledge of the weather. Rather than perfectly predict it, though, they conspire together so that A makes correct predictions and B makes incorrect ones until we eventually suspect A is the best expert. Then, they switch, A making incorrect predictions and B making correct predictions, until we suspect that B is the best expert. This continues indefinitely, forcing us to change our minds infinitely often. And contrary to intuition, it does NOT require the experts be able to see our guesses, provided we’ve nailed down the multiplicative weight algorithm or any other particular algorithm. The experts can merely run that algorithm themselves, allowing them to confuse us even if our guesses are invisible to them. It would be interesting to compute exactly what predictions these mischievous experts would make (this is completely determined, assuming, say, that by coincidence it rains every day).
Some corrections:
1. In both the simplified and general settings, it seems w_{i}^{1} should be 1, not 0.
2. The inequality signs (\leq, \geq) just above the statement of Eq. (1) should be reversed.
[Thanks, fixed now. — L.]