
In which we prove the easy case of Cheeger’s inequality.
1. Expansion and The Second Eigenvalue
Let 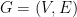


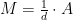
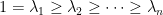

Recall that we defined the edge expansion of a cut 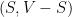

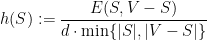
and that the edge expansion of 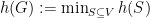
We also defined the related notion of the sparsity of a cut
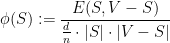
and 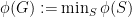
Recall also that in the last lecture we proved that 
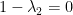

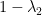
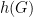
Theorem 1 (Cheeger’s Inequalities)
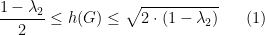
2. The Easy Direction
In this section we prove
Lemma 2
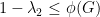
From which we have one direction of Cheeger’s inequality, after recalling that 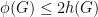
Let us find an equivalent restatement of the sparsest cut problem. If represent a set 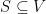

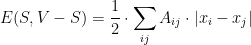
and

so that, after some simplifications, we can write
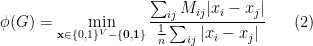
Note that, when 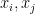
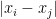

In the last lecture, we gave the following characterization of

Now we claim that the following characterization is also true
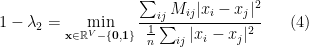
This is because
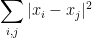
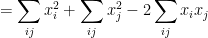
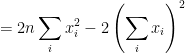
so for every 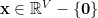
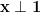
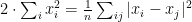

To conclude the argument, take an 

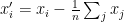
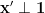

and so we have established (4).
Comparing (4) and (3), it is clear that the quantity 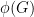
3. Other Relaxations of
Having established that we can view 
Later in the course we will see two more approximation algorithms for sparsest cut and edge expansion. Both are based on continuous relaxations of 
The algorithm of Leighton and Rao is based on a relaxation that is defined by observing that every bit-vector 

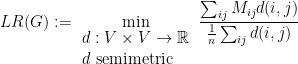
It is not difficult to express 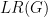
The algorithm of Arora-Rao-Vazirani is obtained by noting that, for a bit-vector 

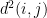
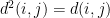
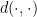
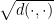
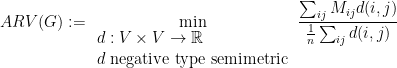
The Arora-Rao-Vazirani relaxation can be expressed as a semi-definite programming problem.
From this discussion it is clear that the Arora-Rao-Vazirani relaxation is a tightening of the Leigthon-Rao relaxation and that we have
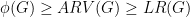
It is less obvious in this treatment, and we will see it later, that the Arora-Rao-Vazirani is also a tightening of the relaxation of

The relaxations

Do you know if there is a version of Cheeger’s inequality that relates to non-uniform sparsest cut?
Pingback: Lecture 8 « Pseudorandomness and Derandomization
Pingback: Lecture 9 « Pseudorandomness and Derandomization
Pingback: Superexpanders: part 1 | Probability, Geometry & Group Theory blog