
In which we look at the linear programming formulation of the maximum flow problem, construct its dual, and find a randomized-rounding proof of the max flow – min cut theorem.
In the first part of the course, we designed approximation algorithms “by hand,” following our combinatorial intuition about the problems. Then we looked at linear programming relaxations of the problems we worked on, and we saw that approximation algorithms for those problems could also be derived by rounding a linear programming solution. We also saw that our algorithms could be interpreted as constructing, at the same time, an integral primal solution and a feasible solution for the dual problem.
Now that we have developed exact combinatorial algorithms for a few problems (maximum flow, minimum s-t cut, global min cut, maximum matching and minimum vertex cover in bipartite graphs), we are going to look at linear programming relaxations of those problems, and use them to gain a deeper understanding of the problems and of our algorithms.
We start with the maximum flow and the minimum cut problems.
1. The LP of Maximum Flow and Its Dual
Given a network 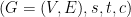
We have one variable 


Now we want to construct the dual.
When constructing the dual of a linear program, it is often useful to rewrite it in a way that has a simpler structure, especially if it is possible to rewrite it in a way that has fewer constraints (which will correspond to fewer dual variables), even at the cost of introducing several new variables in the primal.
A very clean way of formulating the maximum flow problem is to think in terms of the paths along which we are going to send the flow, rather than in terms of how much flow is passing through a specific edge, and this point of view makes the conservation constraints unnecessary.
In the following formulation, we have one variable 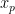




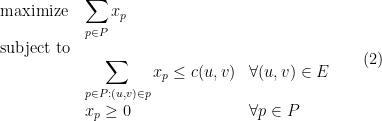
Note that, usually, a network has exponentially many possible paths from
(There are several other cases in combinatorial optimization in which a problem has a easier-to-understand linear programming relaxation or formulation that is exponentially big, and one can prove that it is equivalent to another relaxation or formulation of polynomial size. One then proves theorems about the big linear program, and the theorems apply to the small linear program as well, because of the equivalence. Then the small linear program can be efficiently solved, and the theorems about the big linear program can be turned into efficient algorithms.)
Let us first confirm that indeed (1) and (2) are equivalent.
Fact 1 If
is a feasible solution for (1), then there is a feasible solution for (2) of the same cost.
Proof: Note that this is exactly the Flow Decomposition Theorem that we proved in Lecture 11, in which it is stated as Lemma 2.

Fact 2 If
is a feasible solution for (2), then there is a feasible solution for (1) of the same cost.
Proof: Define
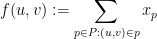
that is, let 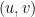
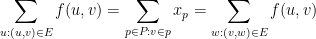
Let us now construct the dual of (2). We have one dual variable 


The linear program (3) is assigning a weight to each edges, which we may think of as a “length,” and the constraints are specifying that, along each possible path,
Fact 3 For every feasible cut
in the network
, there is a feasible solution
to (3) whose cost is the same as the capacity of
Proof: Define 
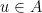

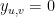

This means that the optimum of (3) is smaller than or equal to the capacity of the minimum cut in the network. Now we are going to describe a randomized rounding method that shows that the optimum of (3) is actually equal to the capacity of the minimum cut. Since the optimum of (3) is equal to the optimum of (2) by the Strong Duality Theorem, and we have proved that the optimum of (3) is equal to the cost of the maximum flow of the network, Lemma 4 below will prove that the cost of the maximum flow in the network is equal to the capacity of the minimum flow, that is, it will be a different proof of the max flow – min cut theorem. It is actually a more difficult proof (because it uses the Strong Duality Theorem whose proof, which we have skipped, is not easy), but it is a genuinely different one, and a useful one to understand, because it gives an example of how to use randomized rounding to solve a problem optimally. (So far, we have only seen examples of the use of randomized rounding to design approximate algorithms.)
Lemma 4 Given any feasible solution
to (3), it is possible to find a cut

Proof: Interpret the 
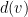
The constraints in (3) imply that 
Pick a value 
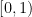

Then, for every choice of
Using linearity of expectation, the average (over the choice of
![\displaystyle \mathop{\mathbb E}_{T \sim [0,1)} capacity(A) = \sum_{(u,v)\in E} c(u,v) \mathop{\mathbb P} [ u\in A \wedge v\not\in A]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+E%7D_%7BT+%5Csim+%5B0%2C1%29%7D+capacity%28A%29+%3D+%5Csum_%7B%28u%2Cv%29%5Cin+E%7D+c%28u%2Cv%29+%5Cmathop%7B%5Cmathbb+P%7D+%5B+u%5Cin+A+%5Cwedge+v%5Cnot%5Cin+A%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
and
![\displaystyle \mathop{\mathbb P} [ u\in A \wedge v\not\in A ] = \mathop{\mathbb P} [ d(u) \leq T < d(v) ] = d(v)-d(u)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D+%5B+u%5Cin+A+%5Cwedge+v%5Cnot%5Cin+A+%5D+%3D+%5Cmathop%7B%5Cmathbb+P%7D+%5B+d%28u%29+%5Cleq+T+%3C+d%28v%29+%5D+%3D+d%28v%29-d%28u%29+&bg=ffffff&fg=000000&s=0&c=20201002)
Finally, we observe the “triangle inequality”

which says that the shortest path from 
Putting all together, we have

and there clearly must exist a choice of
About finding 

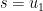


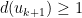

for 

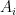
Let us now see what the dual of (1) looks like. It will look somewhat more mysterious than (3), but now we know what to expect: because of the equivalence between (1) and (2), the dual of (1) will have to be a linear programming relaxation of the minimum cut problem, and it will have an exact randomized rounding procedure.
The dual of (1) has one variable for each vertex 

Let us see that (4) is a linear programming relaxation of the minimum cut problem and that it admits an exact rounding algorithm.
Fact 5 If

Proof: Define 

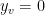

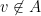

To see that it is a feasible solution, let us first consider the constraints of the first kind. They are always satisfied because if 

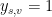
Regarding the constraints of the second kind, we can do a case analysis and see that the constraint is valid if 
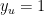


Fact 6 Given a feasible solution of (4), we can find a feasible cut whose capacity is equal to the cost of the solution.
Proof: Pick uniformly at random ![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

This is always a cut, because, by construction, it contains 
Then we have
![\displaystyle \mathop{\mathbb E} capacity(A) = \sum_{u,v} c(u,v) \mathop{\mathbb P} [ u\in A \wedge v \not \in A ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+E%7D+capacity%28A%29+%3D+%5Csum_%7Bu%2Cv%7D+c%28u%2Cv%29+%5Cmathop%7B%5Cmathbb+P%7D+%5B+u%5Cin+A+%5Cwedge+v+%5Cnot+%5Cin+A+%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
It remains to argue that, for every edge
![\displaystyle \mathop{\mathbb P} [ u\in A \wedge v \not \in A ] \leq y_{u,v}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D+%5B+u%5Cin+A+%5Cwedge+v+%5Cnot+%5Cin+A+%5D+%5Cleq+y_%7Bu%2Cv%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
For edges of the form
![\displaystyle \mathop{\mathbb P} [ s\in A \wedge v \not \in A ] = \mathop{\mathbb P} [ v \not\in A ] = \mathop{\mathbb P} [ y_v < T \leq 1 ] = 1-y_v \leq y_{s,v}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D+%5B+s%5Cin+A+%5Cwedge+v+%5Cnot+%5Cin+A+%5D+%3D+%5Cmathop%7B%5Cmathbb+P%7D+%5B+v+%5Cnot%5Cin+A+%5D+%3D+%5Cmathop%7B%5Cmathbb+P%7D+%5B+y_v+%3C+T+%5Cleq+1+%5D+%3D+1-y_v+%5Cleq+y_%7Bs%2Cv%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
(Actually, the above formula applies if 
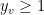


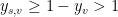
For edges of the form 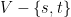
![\displaystyle \mathop{\mathbb P} [ u \in A \wedge v \not \in A] = \mathop{\mathbb P} [ y_v < T \leq y_u ] = y_u-y_v \leq y_{u,v}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D+%5B+u+%5Cin+A+%5Cwedge+v+%5Cnot+%5Cin+A%5D+%3D+%5Cmathop%7B%5Cmathbb+P%7D+%5B+y_v+%3C+T+%5Cleq+y_u+%5D+%3D+y_u-y_v+%5Cleq+y_%7Bu%2Cv%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
(Again, we have to look out for various exceptional cases, such as the case 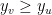

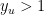
For edges of the form 
![\displaystyle \mathop{\mathbb P} [ v\in A \wedge t \not \in A ] = \mathop{\mathbb P} [ v \in A ] = \mathop{\mathbb P} [ y_v \geq T ] = y_v \leq y_{v,t}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D+%5B+v%5Cin+A+%5Cwedge+t+%5Cnot+%5Cin+A+%5D+%3D+%5Cmathop%7B%5Cmathbb+P%7D+%5B+v+%5Cin+A+%5D+%3D+%5Cmathop%7B%5Cmathbb+P%7D+%5B+y_v+%5Cgeq+T+%5D+%3D+y_v+%5Cleq+y_%7Bv%2Ct%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
(Same disclaimers.)

If you’re working with an optimal solution of the LP in (3) then you don’t even need to optimize over all cuts; any threshold in (0,1) will work deterministically.