
[In the provincial spirit of Italian newspapers, that often have headlines like “Typhoon in South-East Asia causes widespread destruction; what are the consequences for Italian exports?”, and of men who overhear discussions about women’s issue and say things like “yes, but men have issues too,” I am going to comment on how Babai’s announcement affects me and the kind of problems I work on.]
If someone had told me last week: “a quasi-polynomial time algorithm has been found for a major open problem for which only a slightly subexponential algorithm was known before,” I would have immediately thought Unique Games!
Before Babai’s announcement, Graph Isomorphism had certain interesting properties in common with problems such as Factoring, Discrete Log, and Approximate Closest Vector (for approximation ratios of the order of sqrt (n) or more): no polynomial time algorithm is known, non-trivial algorithms that are much faster than brute force are known, and NP-completeness is not possible because the problem belongs to either 

But there is an important difference: there are simple distributions of inputs on which Factoring, Discrete Log, and Closest Vector approximation are believed to be hard on average, and if one proposes an efficiently implementable algorithms for such problems, it can be immediately shown that it does not work. (Or, if it works, it’s already a breakthrough even without a rigorous analysis.)
In the case of Graph Isomorphism, however, it is easy to come up with simple algorithms for which it is very difficult to find counterexamples, and there are algorithms that are rigorously proved to work on certain distributions of random graphs. Now we know that there are in fact no hard instances at all, but, even before, if we believed that Graph Isomorphism was hard, we had to believe that the hard instances were rare and strange, rather than common.
It is also worth pointing out that, using Levin’s theory of average-case complexity, one can show that if any problem at all in NP is hard under any samplable distribution, then for every NP-complete problem we can find a samplable distribution under which the problem is hard. And, in “practice,” natural NP-complete problems do have simple distributions that seem to generate hard instances.
What about Small-set Expansion, Unique Games, and Unique-Games-Hard problems not known to be NP-hard, like 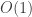
I am sure that it is possible, under standard assumptions, to construct an artificial problem L in NP that is in average-case-P according to Levin’s definition but not in P. Such a problem would not be polynomial time solvable, but it would be easy to solve on average under any samplable distribution and, intuitively, it would be a problem that is hard even though hard instances are rare and strage.
But can a natural problem in NP exhibit this behavior? Now that Graph Isomorphism is not a plausible example any more, I am inclined to believe (until the next surprise) that no natural problem has this behavior, and my guess concerning the Unique Games conjectures is going to be that it is false (or “morally false” in the sense that a quasipolynomial time algorithm exists) until someone comes up with a distribution of Unique Games instances that are plausibly hard on average and that, in particular, exhibit integrality gaps for Lasserre relaxations (even just experimentally).

If we omit constraint that L in NP there is already such a results (about separations average-case and worst-case classes).
For not natural P problems was proven that such a behavior are possible by A. Nickelsen and B. Schelm. in 2005 and for not natural NP problems today was posted more strong result:
http://eccc.hpi-web.de/report/2015/174/
And I’m sure you know how to prove any NP-complete problem is NP-complete if and only if it is not. Can you deny this fact?
I’m quite sure for you this is a fact.
best,
Rafee Kamouna.
If you are willing to broaden your search to search problems, finding a Nash equilibrium also fits in your category, at least under “natural” distributions of instances.
I am happy with plausibly hard samplable distributions as evidence of hardness, even if they are not natural.
I am not following why we “have to” believe that hard instances are hard to find, based on what is written by Luca here. He is not ruling out all simple distributions, so why couldn’t there be a simple distro for generating hard instances, just as there could be a simple algo showing that no hard instance exists?
Yes, that’s a fair point: one may consistently believe that the Unique Games conjecture is true and that Unique Games are hard-on-average under a not-yet-discovered samplable distribution.
When I referred to hypothetical hard instances of Unique Games as “rare and strange” I did not have a specific technical definition in mind, but I was trying to express the point that simple and “spread out” distributions (for example those in which the constraint graph is Erdös-Renyi random) do not hit such hypothetical hard instances in a noticeable way.
Luca, I agree about everything you say in this post.
I wanted to make a separate point about graph isomorphism. Worst-case GI turns out to be *equivalent* to various problems in algorithmic group theory. (Hoffman’s monograph from the early 1980s gives these reductions. http://onlinelibrary.wiley.com/doi/10.1002/zamm.19830630815/abstract) That is probably why it is of paramount interest to Laci, as a leading expert on group theoretic algorithms.
If you think of GI as a problem over groups rather than over graphs, maybe the meaning of “natural distributions” changes. I don’t know enough to be confident either way.
Anyway, congratulations to Laci over finally overcoming his favorite problem after many decade!
Sanjeev
Pingback: Babai breakthru: graph isomorphism in quasipolynomial time | Turing Machine
WHAT IF P = NP?
We define an interesting problem called $MAS$. We show $MAS$ is actually a succinct version of the well known $\textit{NP–complete}$ problem $\textit{SUBSET–PRODUCT}$. When we accept or reject the succinct instances of $MAS$, then we are accepting or rejecting the equivalent and large instances of $\textit{SUBSET–PRODUCT}$. Moreover, we show $MAS \in \textit{NP–complete}$.
In our proof we start assuming that $P = NP$. But, if $P = NP$, then $MAS$ and $\textit{SUBSET–PRODUCT}$ would be in $\textit{P–complete}$, because they are $\textit{NP–complete}$. A succinct version of a problem that is complete for $P$ can be shown not to lie in $P$, because it will be complete for $EXP$. Indeed, in Papadimitriou’s book is proved the following statement: “$NEXP$ and $EXP$ are nothing else but $P$ and $NP$ on exponentially more succinct input”. Since $MAS$ is a succinct version of $\textit{SUBSET–PRODUCT}$ and $\textit{SUBSET–PRODUCT}$ would be in $\textit{P–complete}$, then we obtain that $MAS$ should be also in $\textit{EXP–complete}$.
Since the classes $P$ and $EXP$ are closed under reductions, and $MAS$ is complete for both $P$ and $EXP$, then we could state that $P = EXP$. However, as result of Hierarchy Theorem the class $P$ cannot be equal to $EXP$. To sum up, we obtain a contradiction under the assumption that $P = NP$, and thus, we can claim that $P \neq NP$ as a direct consequence of the Reductio ad absurdum rule.
You could see more on…
https://hal.archives-ouvertes.fr/hal-01233924/document
Best Regards,
Frank.
THE P VERSUS NP PROBLEM
We define an interesting problem called $MAS$. We show $MAS$ is actually a succinct version of the well known $\textit{NP–complete}$ problem $\textit{SUBSET–PRODUCT}$. When we accept or reject the succinct instances of $MAS$, then we are accepting or rejecting the equivalent and large instances of $\textit{SUBSET–PRODUCT}$. Moreover, we show $MAS \in \textit{NP–complete}$.
In our proof we start assuming that $P = NP$. But, if $P = NP$, then $MAS$ and $\textit{SUBSET–PRODUCT}$ would be in $\textit{P–complete}$, because all currently known $\textit{NP–complete}$ are $\textit{NP–complete}$ under logarithmic-space reduction including our new problem $MAS$. A succinct version of a problem that is complete for $P$ can be shown not to lie in $P$, because it will be complete for $EXP$. Indeed, in Papadimitriou’s book is proved the following statement: “$NEXP$ and $EXP$ are nothing else but $P$ and $NP$ on exponentially more succinct input”. Since $MAS$ is a succinct version of $\textit{SUBSET–PRODUCT}$ and $\textit{SUBSET–PRODUCT}$ would be in $\textit{P–complete}$, then we obtain that $MAS$ should be also in $\textit{EXP–complete}$.
Since the classes $P$ and $EXP$ are closed under reductions, and $MAS$ is complete for both $P$ and $EXP$, then we could state that $P = EXP$. However, as result of Hierarchy Theorem the class $P$ cannot be equal to $EXP$. To sum up, we obtain a contradiction under the assumption that $P = NP$, and thus, we can claim that $P \neq NP$ as a direct consequence of the Reductio ad absurdum rule.
You could see more on (version 3)…
https://drive.google.com/file/d/0B3yzKiZO_NmWZ1M1MkNuYVBreXc/view?usp=sharing
Best Regards,
Frank.