Scribed by Keyhan Vakil
In which we complete the study of Independent Set and Max Cut in  random graphs.
random graphs.
1. Maximum Independent Set
Last time we proved an upper bound of 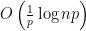 to the probable value of the maximum independent set in a random graph. This bound also holds if
to the probable value of the maximum independent set in a random graph. This bound also holds if  is a function of
is a function of  . There is a simple greedy algorithm which can be shown to achieve an independent set of size
. There is a simple greedy algorithm which can be shown to achieve an independent set of size 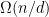 where
where  is the average degree of the graph. For a random graph, this gives us an independent of size
is the average degree of the graph. For a random graph, this gives us an independent of size 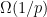 . However we will see how to specialize this analysis to sparse random graphs, and close the remaining gap between the probable value and the greedy algorithm.
. However we will see how to specialize this analysis to sparse random graphs, and close the remaining gap between the probable value and the greedy algorithm.
Consider the greedy algorithm below.
-

- for each
- if
 has no neighbors in
has no neighbors in  then
then 
- return
1.1. First attempt
We might try to model our analysis of this algorithm based on our discussion from Lecture~2.
To wit, let  be the set of vertices not in which have no neighbors in . Let
be the set of vertices not in which have no neighbors in . Let 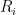 be the size of when contains
be the size of when contains  vertices. If
vertices. If  , then our algorithm outputs an independent set of size
, then our algorithm outputs an independent set of size  . Therefore we can determine the expected size of the algorithm’s output (up to a constant factor) by determining such that
. Therefore we can determine the expected size of the algorithm’s output (up to a constant factor) by determining such that ![{\mathop{\mathbb E}[R_k] = O(1)}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D%5BR_k%5D+%3D+O%281%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
Now we determine ![{\mathop{\mathbb E}[R_{i+1} \mid R_i]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D%5BR_%7Bi%2B1%7D+%5Cmid+R_i%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . A proportion of vertices are connected to the
. A proportion of vertices are connected to the 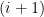 th vertex in expectation. Of the vertices, we expect that
th vertex in expectation. Of the vertices, we expect that  of them will remain unconnected to all the vertices in . This gives us that
of them will remain unconnected to all the vertices in . This gives us that ![{\mathop{\mathbb E}[R_{i+1} \mid R_i] = (1-p)R_i}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D%5BR_%7Bi%2B1%7D+%5Cmid+R_i%5D+%3D+%281-p%29R_i%7D&bg=ffffff&fg=000000&s=0&c=20201002) , and by induction
, and by induction ![{\mathop{\mathbb E}[R_k] = (1-p)^k n}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D%5BR_k%5D+%3D+%281-p%29%5Ek+n%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
Let be such that ![{\mathop{\mathbb E}[R_k] = 1}](https://s0.wp.com/latex.php?latex=%7B%5Cmathop%7B%5Cmathbb+E%7D%5BR_k%5D+%3D+1%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Then:
. Then:
![\displaystyle \mathop{\mathbb E}[R_k] = (1-p)^k n = 1 \implies k = \log_{\frac 1{1-p}} n \approx \frac 1p \ln n](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+E%7D%5BR_k%5D+%3D+%281-p%29%5Ek+n+%3D+1+%5Cimplies+k+%3D+%5Clog_%7B%5Cfrac+1%7B1-p%7D%7D+n+%5Capprox+%5Cfrac+1p+%5Cln+n+&bg=ffffff&fg=000000&s=0&c=20201002)
We conclude that our independent set has expected size  . However if we take
. However if we take  , that would lead us to believe that we could get an independent set of size
, that would lead us to believe that we could get an independent set of size  in a graph with only vertices, which is impossible.
in a graph with only vertices, which is impossible.
The error is that should be  , not
, not 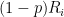 . Note that once we add the th vertex to , it can no longer be in by definition. When is a constant, the difference is negligible, but when is small then the difference becomes more significant.
. Note that once we add the th vertex to , it can no longer be in by definition. When is a constant, the difference is negligible, but when is small then the difference becomes more significant.
It is possible to salvage this analysis, but the result is less elegant. Instead we will now present a different analysis, which will also let us conclude more about higher moments as well.
1.2. Analysis of the greedy algorithm
To analyze the algorithm, consider the following random variables: let 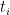 be the number of for-loop iterations between the time the -th element is added to and the time the -th element is added to . We leave undefined if the algorithm terminates with a set of size less than
be the number of for-loop iterations between the time the -th element is added to and the time the -th element is added to . We leave undefined if the algorithm terminates with a set of size less than  . Thus the size of the independent set found by the algorithm is the largest such that
. Thus the size of the independent set found by the algorithm is the largest such that  is defined. Consider the following slightly different probabilistic process: in addition to our graph over vertices
is defined. Consider the following slightly different probabilistic process: in addition to our graph over vertices 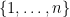 , we also consider a countably infinite number of other vertices
, we also consider a countably infinite number of other vertices 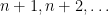 . We sample an infinite super-graph of our graph over this larger vertex set, so that each possible edge has probability of being generated.
. We sample an infinite super-graph of our graph over this larger vertex set, so that each possible edge has probability of being generated.
We continue to run the greedy algorithm for every vertex of this infinite graph, and we call the (now, always defined) number of for-loop iterations between the -th and the -th time that we add a node to . In this revised definition, the size of the independent set found by algorithm in our actual graph is the largest such that  .
.
Now we will reason about the distribution of . Say that we have vertices in and we are trying to determine if we should add some vertex to . Note that the probability of being disconnected from all of is 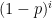 . So we add a vertex at each iteration with probability , which shows that is geometrically distributed with success probability .
. So we add a vertex at each iteration with probability , which shows that is geometrically distributed with success probability .
Based on this, we can find the expected value and variance of our sum from before
![\displaystyle \mathop{\mathbb E} \left[ t_0 + t_1 + \cdots t_{k-1} \right] = \frac { \frac 1 {(1-p)^k} - 1 }{\frac 1 {1-p} - 1} \leq \frac { \frac 1 {(1-p)^k}}{\frac 1 {1-p} - 1} = \frac 1 {p\cdot (1-p)^{k-1}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D+%5Cleft%5B+t_0+%2B+t_1+%2B+%5Ccdots+t_%7Bk-1%7D+%5Cright%5D+%3D+%5Cfrac+%7B+%5Cfrac+1+%7B%281-p%29%5Ek%7D+-+1+%7D%7B%5Cfrac+1+%7B1-p%7D+-+1%7D+%5Cleq+%5Cfrac+%7B+%5Cfrac+1+%7B%281-p%29%5Ek%7D%7D%7B%5Cfrac+1+%7B1-p%7D+-+1%7D+%3D+%5Cfrac+1+%7Bp%5Ccdot+%281-p%29%5E%7Bk-1%7D%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
and likewise
![\displaystyle \begin{array}{rcl} \mathop{\bf Var}[t_0 + t_1 + \cdots t_{k-1}] & \leq & \sum_{i=0}^{k-1} \frac 1 {(1-p)^{2i}} \\ &= & \frac { \frac 1 {(1-p)^{2k}} - 1 }{\frac 1 {(1-p)^2} - 1} \\ & \leq & \frac 1 {(1 - (1-p)^2 ) \cdot (1-p)^{2k-2 } } \\ & \leq & \frac 1 {p \cdot (1-p)^{2k - 2} } \\ & = & p \left( \mathop{\mathbb E}[t_0 + \cdots + t_{k-1}] \right)^2. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%5Cmathop%7B%5Cbf+Var%7D%5Bt_0+%2B+t_1+%2B+%5Ccdots+t_%7Bk-1%7D%5D+%26+%5Cleq+%26+%5Csum_%7Bi%3D0%7D%5E%7Bk-1%7D+%5Cfrac+1+%7B%281-p%29%5E%7B2i%7D%7D+%5C%5C+%26%3D+%26+%5Cfrac+%7B+%5Cfrac+1+%7B%281-p%29%5E%7B2k%7D%7D+-+1+%7D%7B%5Cfrac+1+%7B%281-p%29%5E2%7D+-+1%7D+%5C%5C+%26+%5Cleq+%26+%5Cfrac+1+%7B%281+-+%281-p%29%5E2+%29+%5Ccdot+%281-p%29%5E%7B2k-2+%7D+%7D+%5C%5C+%26+%5Cleq+%26+%5Cfrac+1+%7Bp+%5Ccdot+%281-p%29%5E%7B2k+-+2%7D+%7D+%5C%5C+%26+%3D+%26+p+%5Cleft%28+%5Cmathop%7B%5Cmathbb+E%7D%5Bt_0+%2B+%5Ccdots+%2B+t_%7Bk-1%7D%5D+%5Cright%29%5E2.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
We want to choose so that the sum is at most with high probability. Let

This makes the expected value of the sum 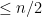 and the standard deviation
and the standard deviation  . Thus, if
. Thus, if  sufficiently fast, the greedy algorithm has a
sufficiently fast, the greedy algorithm has a 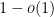 probability of finding an independent set of size
probability of finding an independent set of size 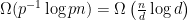 , where
, where  is a measure of the average degree.
is a measure of the average degree.
1.3. Certifiable upper bound
We now derive a polynomial time computable upper bound certificate for maximum independent set in . We use the following lemma without proof. Note its similarity to Lemma~2 from Lecture~1.
Lemma 1 If  ,
,  is sampled from ,
is sampled from ,  is the adjacency matrix of , and
is the adjacency matrix of , and  is the matrix of all ones, then there is a probability that
is the matrix of all ones, then there is a probability that
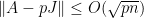
Since  is a real symmetric matrix its spectral norm can be computed as:
is a real symmetric matrix its spectral norm can be computed as:

If is an independent set of size , then  ,
,  , and
, and 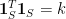 , so that
, so that

This bound holds for any independent set, so it also holds for the largest one. If we denote by 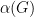 the size of the largest independent set in , we have that
the size of the largest independent set in , we have that

For a random graph, the above upper bound is  with high probability.
with high probability.
2. Max Cut
We will now reconsider Max Cut for the general case . In Lecture~2, we dealt with the special case of  . Unlike maximum independent set, our arguments for the case apply to Max Cut without much modification.
. Unlike maximum independent set, our arguments for the case apply to Max Cut without much modification.
2.1. High probability upper bound
Let be a random graph from , and define  as a measure of its average degree. We will prove that the size of a maximum cut of is at most
as a measure of its average degree. We will prove that the size of a maximum cut of is at most  with high probability. The proof of this statement is nearly identical to the version in Lecture~2, where it was presented for the case . We know that the expected value of a cut is
with high probability. The proof of this statement is nearly identical to the version in Lecture~2, where it was presented for the case . We know that the expected value of a cut is  . By a Chernoff bound, the probability that any particular cut exceeds expectation by an additive factor of
. By a Chernoff bound, the probability that any particular cut exceeds expectation by an additive factor of 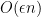 is exponentially decreasing by a factor of
is exponentially decreasing by a factor of  . By taking
. By taking  and taking a union bound over all
and taking a union bound over all  possible cuts , we have that our expected cut has value at most
possible cuts , we have that our expected cut has value at most  with probability
with probability  .
.
2.2. Greedy algorithm
Consider the greedy algorithm
-
-

- for each
- if has more neighbors in
 than in then
than in then 
- else

- return
 .
.
Label 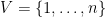 . Let
. Let 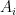 and
and  be the sets and when vertex is considered in the for-loop. For the purpose of analysis, we delay the random decisions in until a vertex is considered. In particular, we delay the choice of which of
be the sets and when vertex is considered in the for-loop. For the purpose of analysis, we delay the random decisions in until a vertex is considered. In particular, we delay the choice of which of 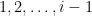 is a neighbor until is vertex is considered. Note that no edge needs to be considered twice, and so we can treat each one as an independent biased coin flip.
is a neighbor until is vertex is considered. Note that no edge needs to be considered twice, and so we can treat each one as an independent biased coin flip.
Let  and
and 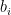 be the neighbors of in and respectively. We can show that
be the neighbors of in and respectively. We can show that  , and so
, and so  is the gain our algorithm achieves over cutting half the edges.
is the gain our algorithm achieves over cutting half the edges.
Now 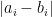 has expectation
has expectation  and variance
and variance  . Adding over all , the sum of the differences has mean
. Adding over all , the sum of the differences has mean 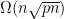 and variance
and variance 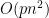 . This gives us an expected gain of
. This gives us an expected gain of  with probability. The value of cutting half the edges is approximately
with probability. The value of cutting half the edges is approximately 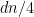 . This gives a final value of
. This gives a final value of  w.h.p. as stated.
w.h.p. as stated.
2.3. Certifiable upper bound
Again, we will derive a certifiable upper bound by looking at the spectral norm. If 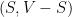 is a cut with value
is a cut with value 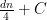 , then we have
, then we have



so

This means that, in every graph, the maximum cut is upper bounded by

which if  is with high probability at most
is with high probability at most 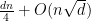 (by Lemma~1).
(by Lemma~1).
3. Conclusion
We conclude with the following table, which summarizes our results for a random graph sampled from  .
.
| Problem |
Expected Value |
Greedy Algorithm |
Certifiable Upper Bound |
| Independent Set |
 |
 w.h.p. w.h.p. |
 w.h.p.* w.h.p.* |
| Max Cut |
 |
 w.h.p. w.h.p. |
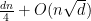 w.h.p.* w.h.p.* |
* Note that both certifiable upper bounds require .
Both greedy algorithms perform very well in comparison to the probable value. In Max~Cut, our greedy algorithm is particularly strong, matching our certifiable upper bound up to a lower order term. This supports one of our major theses: while greedy algorithms exhibit poor worst-case performance, they tend to do well over our given distribution.

