The multiplicative weights or hedge algorithm is the most well known and most frequently rediscovered algorithm in online optimization.
The problem it solves is usually described in the following language: we want to design an algorithm that makes the best possible use of the advice coming from  self-described experts. At each time step
self-described experts. At each time step  , the algorithm has to decide with what probability to follow the advice of each of the experts, that is, the algorithm has to come up with a probability distribution
, the algorithm has to decide with what probability to follow the advice of each of the experts, that is, the algorithm has to come up with a probability distribution 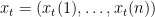 where
where  and
and 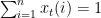 . After the algorithm makes this choice, it is revealed that following the advice of expert
. After the algorithm makes this choice, it is revealed that following the advice of expert  at time
at time  leads to loss
leads to loss  , so that the expected loss of the algorithm at time is
, so that the expected loss of the algorithm at time is  . A loss can be negative, in which case its absolute value can be interpreted as a profit.
. A loss can be negative, in which case its absolute value can be interpreted as a profit.
After  steps, the algorithm “regrets” that it did not just always follow the advice of the expert that, with hindsight, was the best one, so that the regret of the algorithm after steps is
steps, the algorithm “regrets” that it did not just always follow the advice of the expert that, with hindsight, was the best one, so that the regret of the algorithm after steps is

This corresponds to the instantiation of the framework we described in the previous post to the special case in which the set of feasible solutions  is the set
is the set  of probability distributions over the sample space
of probability distributions over the sample space  and in which the loss functions
and in which the loss functions  are linear functions of the form
are linear functions of the form  . In order to bound the regret, we also have to bound the “magnitude” of the loss functions, so in the following we will assume that for all and all we have
. In order to bound the regret, we also have to bound the “magnitude” of the loss functions, so in the following we will assume that for all and all we have 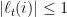 , and otherwise we can scale everything by a known upper bound on
, and otherwise we can scale everything by a known upper bound on  .
.
We now describe the algorithm.
The algorithm maintains at each step a vector of weights  which is initialized as
which is initialized as  . The algorithm performs the following operations at time :
. The algorithm performs the following operations at time :
That is, the weight of expert at time is  , and the probability
, and the probability 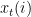 of following the advice of expert at time is proportional to the weight. The parameter
of following the advice of expert at time is proportional to the weight. The parameter  is hardwired into the algorithm and we will optimize it later. Note that the algorithm gives higher weight to experts that produced small losses (or negative losses of large absolute value) in the past, and thus puts higher probability on such experts.
is hardwired into the algorithm and we will optimize it later. Note that the algorithm gives higher weight to experts that produced small losses (or negative losses of large absolute value) in the past, and thus puts higher probability on such experts.
We will prove the following bound.
Theorem 1 Assuming that for all and we have 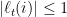 , for every
, for every 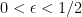 , after steps the multiplicative weight algorithm experiences a regret that is always bounded as
, after steps the multiplicative weight algorithm experiences a regret that is always bounded as
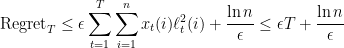
In particular, if  , by setting
, by setting  we achieve a regret bound
we achieve a regret bound

We will start by giving a short proof of the above theorem.
For each time step , define the quantity

We want to prove that, roughly speaking, the only way for an adversary to make the algorithm incur a large loss is to produce a sequence of loss functions such that even the best expert incurs a large loss. The proof will work by showing that if the algorithm incurs a large loss after steps, then  is small, and that if is small, then even the best expert incurs a large loss.
is small, and that if is small, then even the best expert incurs a large loss.
Let us define

to be the loss of the best expert. Then we have
Lemma 2 (If is small, then 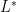 is large)
is large)
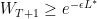
Proof: Let  be an index such that
be an index such that  . Then we have
. Then we have


Lemma 3 (If the loss of the algorithm is large then is small)

where  is the vector whose -th coordinate is
is the vector whose -th coordinate is 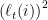
Proof: Since we know that  , it is enough to prove that, for every
, it is enough to prove that, for every  , we have
, we have
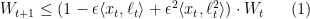
And we see that





where we used the definitions of our quantities and the fact that  for
for  .
.
Using the fact that  for all
for all  , the above lemmas can be restated as
, the above lemmas can be restated as
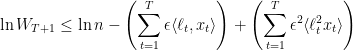
and
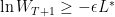
which together imply
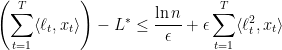
as desired.
Personally, I find all of the above very unsatisfactory, because both the algorithm and the analysis, but especially the analysis, seem to come out of nowhere. In fact, I never felt that I actually understood this analysis until I saw it presented as a special case of the Follow The Regularized Leader framework that we will discuss in a future post. (We will actually prove a slightly weaker bound, but with a much more satisfying proof.)
Here is, however, a story of how a statistical physicist might have invented the algorithm and might have come up with the analysis. Let’s call the loss caused by expert after  steps the energy of expert at time :
steps the energy of expert at time :

Note that we have defined it in such a way that the algorithm knows 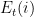 at time . Our offline optimum is the energy of the lowest energy expert at time
at time . Our offline optimum is the energy of the lowest energy expert at time  , that, is, the energy of the ground state at time . When we have a collection of numbers
, that, is, the energy of the ground state at time . When we have a collection of numbers  , a nice lower bound to their minimum is
, a nice lower bound to their minimum is
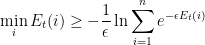
which is true for every 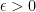 . The right-hand side above is the free energy at temperature
. The right-hand side above is the free energy at temperature  at time . This seems like the kind of expression that we could use to bound the offline optimum, so let’s give it a name
at time . This seems like the kind of expression that we could use to bound the offline optimum, so let’s give it a name

In terms of coming up with an algorithm, all that we have got to work with at time are the losses of the experts at times 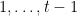 . If the adversary chooses to make one of the experts consistently much better than the others, it is clear that, in order to get any reasonable regret bound, the algorithm will have to put much of the probability mass in most of the steps on that expert. This suggests that the
. If the adversary chooses to make one of the experts consistently much better than the others, it is clear that, in order to get any reasonable regret bound, the algorithm will have to put much of the probability mass in most of the steps on that expert. This suggests that the  should put higher probability on experts that have done well in the first steps, that is should put higher probability on “lower-energy” experts. When we have a system in which, at time , state has energy , a standard distribution that puts higher probability on lower energy states is the Gibbs distribution at temperature
should put higher probability on experts that have done well in the first steps, that is should put higher probability on “lower-energy” experts. When we have a system in which, at time , state has energy , a standard distribution that puts higher probability on lower energy states is the Gibbs distribution at temperature 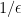 , defined as
, defined as

where the denominator above is also called the partition function at time

So far we have “rediscovered” our multiplicative weights algorithm, and the quantity  that we had in our analysis gets interpreted as the partition function
that we had in our analysis gets interpreted as the partition function 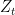 . The fact that
. The fact that 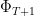 bounds the offline optimum suggests that we should use
bounds the offline optimum suggests that we should use  as a potential function, and aim for an analysis involving a telescoping sum. Indeed some manipulations (the same as in the short proof above, but which are now more mechanical) give that the loss of the algorithm at time is
as a potential function, and aim for an analysis involving a telescoping sum. Indeed some manipulations (the same as in the short proof above, but which are now more mechanical) give that the loss of the algorithm at time is

which telescopes to give
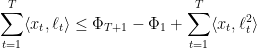
Recalling that

and

we have again

As mentioned above, we will give a better story when we get to the Follow The Regularized Leader framework. In the next post, we will discuss complexity-theory consequences of the result we just proved.


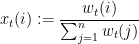

Very nice writeup!
The intuition that makes the analysis clear to me is the following:
– if an expert makes a mistake, its weight goes down by some factor.
– if we make a mistake, the _total_ weight goes down by some (other) factor.
– if we made much more mistakes than the expert, the total would go down so much that the expert’s weight would not fit in it 🙂
Hi Luca,
I think there is a typo right after you state Lemma 3, the product goes from 1 to T (and not n) as you are iterating over time and not the experts.
Pingback: Online Optimization Post 7: Matrix Multiplicative Weights Update | in theory