A conjectural approaches to the Riemann hypothesis is to find a correspondence between the zeroes of the zeta function and the eigenvalues of a linear operator. This was first conceived by Hilbert and by Pólya in the 1910s. (See this correspondence with Odlyzko.) In the subsequent century, there have been a number of rigorous results relating the zeroes of zeta functions in other settings to eigenvalues of linear operators. There is also a connection between the distribution of known zeroes of the Riemann zeta function, as derived from explicit calculations, and the distribution of eigenvalues of the Gaussian unitary ensemble.
In a previous post we talked about the definition of the Ihara zeta function of a graph, and Ihara’s explicit formula for it, in terms of a determinant that is closely related to the characteristic polynomial of the adjacency matrix of the graph, so that the zeroes of the zeta function determine the eigenvalue of the graph. And if the zeta function of the graph satisfies a “Riemann hypothesis,” meaning that, after a change of variable, all zeroes and poles of the zeta function are  in absolute value, then the graph is Ramanujan. Conversely, if the graph is Ramnujan then its Ihara zeta function must satisfy the Riemann hypothesis.
in absolute value, then the graph is Ramanujan. Conversely, if the graph is Ramnujan then its Ihara zeta function must satisfy the Riemann hypothesis.
As I learned from notes by Pete Clark, the zeta functions of curves and varieties in finite fields also involve a determinant, and the “Riemann hypothesis” for such curves is a theorem (proved by Weil for curves and by Deligne for varieties), which says that (after an analogous change of variable) all zeroes and poles of the zeta function must be  in absolute value, where
in absolute value, where  is the size of the finite field. This means that one way to prove that a family of
is the size of the finite field. This means that one way to prove that a family of  -regular graphs is Ramanujan is to construct for each graph
-regular graphs is Ramanujan is to construct for each graph  in the family a variety
in the family a variety 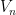 over
over  such that the determinant that comes up in the zeta function of is the “same” (up to terms that don’t affect the roots, and to the fact that if
such that the determinant that comes up in the zeta function of is the “same” (up to terms that don’t affect the roots, and to the fact that if  is a root for one characteristic polynomial, then
is a root for one characteristic polynomial, then 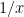 has to be a root for the other) as the determinant that comes up in the zeta function of the variety . Clark shows that one can constructs such families of varieties (in fact, curves are enough) for all the known algebraic constructions of Ramanujan graphs, and one can use families of varieties for which the corresponding determinant is well understood to give new constructions. For example, for every
has to be a root for the other) as the determinant that comes up in the zeta function of the variety . Clark shows that one can constructs such families of varieties (in fact, curves are enough) for all the known algebraic constructions of Ramanujan graphs, and one can use families of varieties for which the corresponding determinant is well understood to give new constructions. For example, for every  , if
, if  is the number of distinct prime divisors of
is the number of distinct prime divisors of  (which would be one if is a prime power) Clark gets a family of graphs with second eigenvalue
(which would be one if is a prime power) Clark gets a family of graphs with second eigenvalue 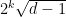 . (The notes call the number of distinct prime divisors of , but it must be a typo.)
. (The notes call the number of distinct prime divisors of , but it must be a typo.)
So spectral techniques underlie fundamental results in number theory and algebraic geometry, which then give us expander graphs. Sounds like something that we (theoretical computer scientists) should know more about.
The purpose of these notes is to explore a bit more the statements of these results, although we will not even begin to discuss their proofs.
One more reason why I find this material very interesting is that all the several applications of polynomials in computer science (to constructing error-correcting codes, secret sharing schemes, -wise independent generators, expanders of polylogarithmic degree, giving the codes used in PCP constructions, self-reducibility of the permanent, proving combinatorial bounds via the polynomial method, and so on), always eventually rely on three things:
This is enough to explain the remarkable pseudo-randomness of constructions that we get out of polynomials, and it is the set of principles that underlie much of what is below, except that we are going to restrict polynomials to the set of zeroes of another polynomial, instead of a line, and this is where things get much more complicated, and interesting.
Before getting started, however, I would like to work out a toy example (which is closely related to what goes on with the Ihara zeta function) showing how an expression that looks like the one defining zeta functions can be expressed as a characteristic polynomial of a linear operator, and how its roots (which are then the eigenvalues of the operator) help give bound to a counting problem, and how one can get such bounds directly from the trace of the operator.
If we have quantities  that we want to bound, then the “zeta function” of the sequence is
that we want to bound, then the “zeta function” of the sequence is
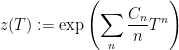
For example, and this will be discussed in more detail below, if  if a bivariate polynomial over , we may be interested in the number
if a bivariate polynomial over , we may be interested in the number 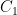 of solutions of the equation
of solutions of the equation  over , as well as the number of solutions over the extension
over , as well as the number of solutions over the extension 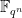 . In this case, the zeta function of the curve defined by
. In this case, the zeta function of the curve defined by  is precisely
is precisely
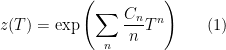
and Weil proved that 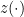 is a rational function, and that if
is a rational function, and that if  are the zeroes and poles of
are the zeroes and poles of  , that is, the roots of the numerator and the denominator, then they are all at most in absolute value, and one has
, that is, the roots of the numerator and the denominator, then they are all at most in absolute value, and one has
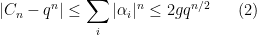
How does one get an approximate formula for as in (2) from the zeroes of a function like (1), and what do determinants and traces have got to do with it?
Here is our toy example: suppose that we have a graph  and that
and that  is the number of cycles of the graph of length
is the number of cycles of the graph of length  . Here by “cycle of length ” we mean a sequence
. Here by “cycle of length ” we mean a sequence 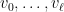 of vertices such that
of vertices such that  and, for
and, for 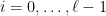 ,
, 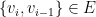 . So, for example, in a graph in which the vertices
. So, for example, in a graph in which the vertices 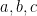 form a triangle,
form a triangle, 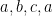 and
and  are two distinct cycles of length 3, and
are two distinct cycles of length 3, and 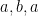 is a cycle of length 2.
is a cycle of length 2.
We could define the function
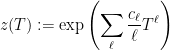
and hope that its zeroes have to do with the computation of , and that  can be defined in terms of the characteristic polynomial.
can be defined in terms of the characteristic polynomial.
Indeed, we have (remember,  is a complex number, not a matrix):
is a complex number, not a matrix):
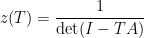
and, if  are the zeroes and poles of
are the zeroes and poles of  , then
, then
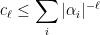
How did we get these bounds? Well, we cheated because we already knew that  , where
, where  are the eigenvalues of
are the eigenvalues of  . This means that
. This means that
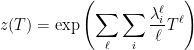
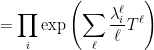

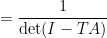
Where we used 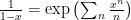 . Now we see that the poles of are precisely the inverses of the eigenvalues of .
. Now we see that the poles of are precisely the inverses of the eigenvalues of .
Now we are ready to look more closely at various zeta functions.
I would like to thank Ken Ribet and Jared Weinstein for the time they spent answering questions. Part of this post will follow, almost word for word, this post of Terry Tao. All the errors and misconceptions below, however, are my own original creation.
Continue reading →




 and the work of Helfgott and Seress on the diameter of permutation groups.
and the work of Helfgott and Seress on the diameter of permutation groups. we can always find an univariate polynomial of degree
we can always find an univariate polynomial of degree  .
.
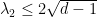 , and we would certainly be very happy with a family of graphs in which
, and we would certainly be very happy with a family of graphs in which 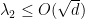 .
.
 is a group with operation
is a group with operation  and
and 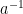 is the inverse of element
is the inverse of element  , and
, and  is a symmetric set of generators, then the Cayley graph
is a symmetric set of generators, then the Cayley graph 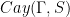 is the graph whose vertices are the elements of
is the graph whose vertices are the elements of  such that
such that 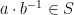 .
.
 , where
, where  is the number of vertices. Even with such high degree, the weak version of the Alon-Boppana theorem still implies that we must have
is the number of vertices. Even with such high degree, the weak version of the Alon-Boppana theorem still implies that we must have 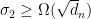 , and so we will be happy if we get a graph in which
, and so we will be happy if we get a graph in which  . Highly expanding graphs of degree
. Highly expanding graphs of degree  are interesting because they have some of the properties of random graphs from the
are interesting because they have some of the properties of random graphs from the  distribution. In turn, graphs from
distribution. In turn, graphs from  is a prime,
is a prime, 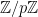 is the group of addition modulo
is the group of addition modulo  is the set of elements of
is the set of elements of  of the form
of the form  , then the graph is just
, then the graph is just  . That is, the graph has a vertex
. That is, the graph has a vertex  for each
for each  , and two vertices
, and two vertices  are adjacent if and only if there is an
are adjacent if and only if there is an  such that
such that  .
.
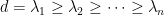
 be?
be? 
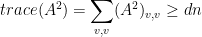
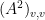 counts the paths that go from
counts the paths that go from 

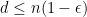 is necessary to get lower bounds of
is necessary to get lower bounds of  ; in the clique, for example, we have
; in the clique, for example, we have 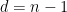 and
and 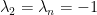 .
.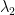 , and in fact it is possible to have
, and in fact it is possible to have 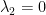 and
and 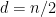 , for example in the bipartite complete graph.
, for example in the bipartite complete graph.  . Let
. Let  ,
, 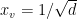 if
if  and
and 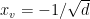 if
if  . Note that there cannot be any edge between a neighbor of
. Note that there cannot be any edge between a neighbor of  , that
, that  (because there are
(because there are 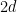 edges, each counted twice, that give a contribution of
edges, each counted twice, that give a contribution of  to
to 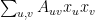 ) and that
) and that  .
.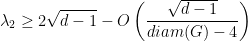
 is the diameter of
is the diameter of  , then one must have
, then one must have 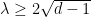 . This is why families of Ramanujan graphs, in which
. This is why families of Ramanujan graphs, in which  be
be 
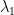 , that is, if we define
, that is, if we define
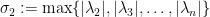
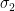 is small. The expander mixing lemma is the fact that for every two disjoint sets
is small. The expander mixing lemma is the fact that for every two disjoint sets 
 the matrix that has ones everywhere, then
the matrix that has ones everywhere, then

 and
and 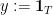 in the above expression and do the calculations.
in the above expression and do the calculations. , where
, where  is the diagonal matrix such that
is the diagonal matrix such that 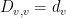 , where
, where 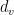 is the degree of
is the degree of 

 .
. 
 the average degree, so that
the average degree, so that  . Now we have
. Now we have
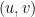 exists with probability
exists with probability 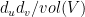 , up to an error that depends on
, up to an error that depends on 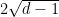 . We will see what this means and how to prove it.
. We will see what this means and how to prove it.
 comes up often, where
comes up often, where 