In the last post we introduced the following problem: we are given a length-increasing function, the hardest case being a function  whose output is one bit longer than the input, and we want to construct a generator
whose output is one bit longer than the input, and we want to construct a generator  such that the advantage or distinguishing probability of
such that the advantage or distinguishing probability of
![\displaystyle \left| \mathop{\mathbb P}_{z \in \{ 0,1 \}^{n-1}} [D(G(z)) =1 ] - \mathop{\mathbb P}_{x \in \{ 0,1 \}^{n}} [D(x) =1 ] \right| \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%5Cleft%7C+%5Cmathop%7B%5Cmathbb+P%7D_%7Bz+%5Cin+%5C%7B+0%2C1+%5C%7D%5E%7Bn-1%7D%7D+%5BD%28G%28z%29%29+%3D1+%5D+-+%5Cmathop%7B%5Cmathbb+P%7D_%7Bx+%5Cin+%5C%7B+0%2C1+%5C%7D%5E%7Bn%7D%7D+%5BD%28x%29+%3D1+%5D+%5Cright%7C+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
is as large as possible relative to the circuit complexity of .
I will show how to achieve advantage  with a circuit of size
with a circuit of size  . Getting rid of the suboptimal factor of
. Getting rid of the suboptimal factor of  is a bit more complicated. These results are in this paper.
is a bit more complicated. These results are in this paper.
Let us review some well known facts about distinguishability of distributions. If  and
and  are two distributions over
are two distributions over  , then the advantage of the best distinguisher between and is called the statistical distance (or total variation distance) between and , and is denoted
, then the advantage of the best distinguisher between and is called the statistical distance (or total variation distance) between and , and is denoted  , hence
, hence
![\displaystyle ||X-Y||_{SD} := \max_{D:\{ 0,1 \}^n \rightarrow \{ 0,1 \}} \left| \mathop{\mathbb P}_{x\sim X} [ D(x)=1] - \mathop{\mathbb P}_{y\sim Y} [ D(y)=1] \right| \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7C%7CX-Y%7C%7C_%7BSD%7D+%3A%3D+%5Cmax_%7BD%3A%5C%7B+0%2C1+%5C%7D%5En+%5Crightarrow+%5C%7B+0%2C1+%5C%7D%7D+%5Cleft%7C+%5Cmathop%7B%5Cmathbb+P%7D_%7Bx%5Csim+X%7D+%5B+D%28x%29%3D1%5D+-+%5Cmathop%7B%5Cmathbb+P%7D_%7By%5Csim+Y%7D+%5B+D%28y%29%3D1%5D+%5Cright%7C+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
and it is easy to see that the statistical distance between two distributions is half their 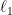 distance, if we think of them as vectors, that is
distance, if we think of them as vectors, that is
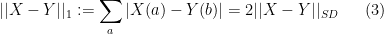
If 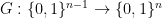 is a length-increasing function, then the distribution of outputs
is a length-increasing function, then the distribution of outputs 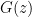 of the function (given a random input seed
of the function (given a random input seed  ) has statistical distance at least
) has statistical distance at least  from the uniform distribution, as seen by using the distinguisher defined as
from the uniform distribution, as seen by using the distinguisher defined as

because outputs 1 with probability one given an output of  , but with probability at most
, but with probability at most 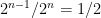 given a uniformly sampled element of .
given a uniformly sampled element of .
We are asking the question of whether there necessarily has to be a computable by a relatively small circuit which has non-trivially good advantage in distinguishing from the uniform distribution.
It has been well known since the 1980s (see the introduction of this survey paper by Oded Goldreich) that for every distribution
![\displaystyle || X- U_n ||_{SD} = O(\sqrt{2^n}) \cdot \max_L \left| \mathop{\mathbb P}_{x\sim X} [L(x) = 1] - \mathop{\mathbb P}_{x\sim U_n} [L(x)=1] \right| \ \ \ \ \ (4)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%7C%7C+X-+U_n+%7C%7C_%7BSD%7D+%3D+O%28%5Csqrt%7B2%5En%7D%29+%5Ccdot+%5Cmax_L+%5Cleft%7C+%5Cmathop%7B%5Cmathbb+P%7D_%7Bx%5Csim+X%7D+%5BL%28x%29+%3D+1%5D+-+%5Cmathop%7B%5Cmathbb+P%7D_%7Bx%5Csim+U_n%7D+%5BL%28x%29%3D1%5D+%5Cright%7C+%5C+%5C+%5C+%5C+%5C+%284%29&bg=ffffff&fg=000000&s=0&c=20201002)
where the maximum is taken over all the  -linear functions
-linear functions  , and where
, and where 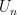 is the uniform distribution over . This fact, which has an easy proof using Fourier analysis, is useful in showing that certain distributions over -bit strings are nearly uniform, because (up to some loss which is tolerable if is small) it reduces this task to the task of showing that the xors of all subsets of the bits of the string are nearly unbiased.
is the uniform distribution over . This fact, which has an easy proof using Fourier analysis, is useful in showing that certain distributions over -bit strings are nearly uniform, because (up to some loss which is tolerable if is small) it reduces this task to the task of showing that the xors of all subsets of the bits of the string are nearly unbiased.
Here we are interested in the implication that if  is a length-increasing function then there exists a linear function
is a length-increasing function then there exists a linear function  such that
such that
![\displaystyle \left| \mathop{\mathbb P}_{z\sim \{ 0,1 \}^{n-1}} [ L(G(z)) = 1] - \mathop{\mathbb P}_{x\sim \{ 0,1 \}^n} [ L(x)=1] \right| \geq \Omega \left( \frac 1 {\sqrt{2^n}} \right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cleft%7C+%5Cmathop%7B%5Cmathbb+P%7D_%7Bz%5Csim+%5C%7B+0%2C1+%5C%7D%5E%7Bn-1%7D%7D+%5B+L%28G%28z%29%29+%3D+1%5D+-+%5Cmathop%7B%5Cmathbb+P%7D_%7Bx%5Csim+%5C%7B+0%2C1+%5C%7D%5En%7D+%5B+L%28x%29%3D1%5D+%5Cright%7C+%5Cgeq+%5COmega+%5Cleft%28+%5Cfrac+1+%7B%5Csqrt%7B2%5En%7D%7D+%5Cright%29+&bg=ffffff&fg=000000&s=0&c=20201002)
This means that one can achieve distinguishing probability 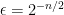 with a circuit of size
with a circuit of size  , which has the promised size .
, which has the promised size .
How do we “scale up” this result? For example, how do we achieve distinguishing probability  with a circuit of size
with a circuit of size  ?
?
By analogy with our simplified proof of a result of Andreev, Clementi and Rolim that I described last week, we might try the following approach:
- partition
 into
into 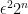 sets, each of size
sets, each of size  ;
;
- find the linear function that is the best distinguisher within each set;
- create a distinguisher that, on input
 , determines the set that belongs to, and then applies to the appropriate linear function.
, determines the set that belongs to, and then applies to the appropriate linear function.
The problem with this approach is how to define “best distinguisher within a set.” Our initial idea was to consider, for each set  in the partition, the distribution
in the partition, the distribution  versus the uniform distribution over , and then find the best linear distinguisher for each of these pairs of distributions. Unfortunately this approach runs into various difficulties if the distribution does not hit the various sets in the partition with approximately the same probability. Our solution was to define the partition using pairwise independent hashing, which would have the effect that would hit the various sets with approximately the same probability. (This is the solution that I presented when I gave talks about this result in Princeton and New York.)
versus the uniform distribution over , and then find the best linear distinguisher for each of these pairs of distributions. Unfortunately this approach runs into various difficulties if the distribution does not hit the various sets in the partition with approximately the same probability. Our solution was to define the partition using pairwise independent hashing, which would have the effect that would hit the various sets with approximately the same probability. (This is the solution that I presented when I gave talks about this result in Princeton and New York.)
Fortunately, there is a much easier and attractive way to proceed. Just partition into sets, each of size based on the value of the first  bits. Then, for each set in the partition
bits. Then, for each set in the partition 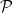 , find the affine function
, find the affine function  that maximizes
that maximizes
![\displaystyle \mathop{\mathbb P}_{z\sim \{ 0,1 \}^{n-1}} [ L_S(G(z)) = 1 \wedge G(z) \in S ] - \mathop{\mathbb P}_{x\sim \{ 0,1 \}^{n}} [ L_S(x) = 1 \wedge x \in S ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+P%7D_%7Bz%5Csim+%5C%7B+0%2C1+%5C%7D%5E%7Bn-1%7D%7D+%5B+L_S%28G%28z%29%29+%3D+1+%5Cwedge+G%28z%29+%5Cin+S+%5D+-+%5Cmathop%7B%5Cmathbb+P%7D_%7Bx%5Csim+%5C%7B+0%2C1+%5C%7D%5E%7Bn%7D%7D+%5B+L_S%28x%29+%3D+1+%5Cwedge+x+%5Cin+S+%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
and then define the distinguisher

(where  is the characteristic function of ) that, given , determines which set of the partition belongs to and then returns
is the characteristic function of ) that, given , determines which set of the partition belongs to and then returns 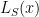 .
.
The distinguisher can clearly be evaluated by a circuit of size , so it remains to understand its distinguishing probability. The main claim is that for every set there is an affine function such that
![\displaystyle \geq \frac 12 \mathop{\mathbb P}_{z\sim \{ 0,1 \}^{n-1}} [ G(z) \in S] - \frac 12 \mathop{\mathbb P}_{x\sim \{ 0,1 \}^n} [x\in S]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cgeq+%5Cfrac+12+%5Cmathop%7B%5Cmathbb+P%7D_%7Bz%5Csim+%5C%7B+0%2C1+%5C%7D%5E%7Bn-1%7D%7D+%5B+G%28z%29+%5Cin+S%5D+-+%5Cfrac+12+%5Cmathop%7B%5Cmathbb+P%7D_%7Bx%5Csim+%5C%7B+0%2C1+%5C%7D%5En%7D+%5Bx%5Cin+S%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle +\Omega\left( \frac 1 {\sqrt{|S|}} \right ) \cdot \sum_{a\in S} \left| \mathop{\mathbb P}_{z\sim \{ 0,1 \}^{n-1}} [G(z)=a] - \frac 1 {2^n} \right| \ \ \ \ \ (5)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+++%2B%5COmega%5Cleft%28+%5Cfrac+1+%7B%5Csqrt%7B%7CS%7C%7D%7D+%5Cright+%29+%5Ccdot+%5Csum_%7Ba%5Cin+S%7D+%5Cleft%7C+%5Cmathop%7B%5Cmathbb+P%7D_%7Bz%5Csim+%5C%7B+0%2C1+%5C%7D%5E%7Bn-1%7D%7D+%5BG%28z%29%3Da%5D+-+%5Cfrac+1+%7B2%5En%7D+%5Cright%7C+%5C+%5C+%5C+%5C+%5C+%285%29&bg=ffffff&fg=000000&s=0&c=20201002)
and if we sum these inequalities over all the sets we get the distinguishing probability of on the left-hand side and 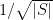 times the distance of from the uniform distribution on the right-hand side. Then the distinguishing probability of is at least
times the distance of from the uniform distribution on the right-hand side. Then the distinguishing probability of is at least  , and the sets were chosen to have size .
, and the sets were chosen to have size .
How does one prove (5)? More importantly, how does one begin to guess that an equation like (5) is true and that it provides the right “amortization” between the advantage within a block and the relative probabilities of hitting the block? And how is this any simpler than what we were doing before?
The answer is that everything becomes much simpler (and one does not have to reason about anything as messy as (5)) if we represent bits with 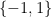 instead of
instead of  and we observe that our original goal is to find an efficient distinguisher
and we observe that our original goal is to find an efficient distinguisher 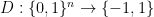 such that
such that

where  and
and 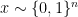 , because
, because
![\displaystyle \begin{array}{rcl} \mathop{\mathbb E} D(G(z)) & = & \mathop{\mathbb P} [ D(G(z)) =1] - \mathop{\mathbb P} [ D(G(z)) = -1 ] \\ & = & 2 \mathop{\mathbb P} [D(G(z))=1] - 1 \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D+%5Cmathop%7B%5Cmathbb+E%7D+D%28G%28z%29%29+%26+%3D+%26+%5Cmathop%7B%5Cmathbb+P%7D+%5B+D%28G%28z%29%29+%3D1%5D+-+%5Cmathop%7B%5Cmathbb+P%7D+%5B+D%28G%28z%29%29+%3D+-1+%5D+%5C%5C+%26+%3D+%26+2+%5Cmathop%7B%5Cmathbb+P%7D+%5BD%28G%28z%29%29%3D1%5D+-+1+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
and same for 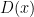 , so
, so
![\displaystyle \mathop{\mathbb E} D(G(z)) - \mathop{\mathbb E} D(x) = 2\cdot\left( \mathop{\mathbb P} [ D(G(z)) = 1] - \mathop{\mathbb P} [ D(x) = 1] \right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+E%7D+D%28G%28z%29%29+-+%5Cmathop%7B%5Cmathbb+E%7D+D%28x%29+%3D+2%5Ccdot%5Cleft%28+%5Cmathop%7B%5Cmathbb+P%7D+%5B+D%28G%28z%29%29+%3D+1%5D+-+%5Cmathop%7B%5Cmathbb+P%7D+%5B+D%28x%29+%3D+1%5D+%5Cright%29+&bg=ffffff&fg=000000&s=0&c=20201002)
Our goal can also be written as proving
![\displaystyle \sum_{a\in \{ 0,1 \}^n} D(a)\cdot \left( \mathop{\mathbb P} [G(z)=a] - \frac 1 {2^n} \right) \geq 2\epsilon](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csum_%7Ba%5Cin+%5C%7B+0%2C1+%5C%7D%5En%7D+D%28a%29%5Ccdot+%5Cleft%28+%5Cmathop%7B%5Cmathbb+P%7D+%5BG%28z%29%3Da%5D+-+%5Cfrac+1+%7B2%5En%7D+%5Cright%29+%5Cgeq+2%5Cepsilon+&bg=ffffff&fg=000000&s=0&c=20201002)
and if we write ![{g(a):= \left( \mathop{\mathbb P} [G(z)=a] - \frac 1 {2^n} \right)}](https://s0.wp.com/latex.php?latex=%7Bg%28a%29%3A%3D+%5Cleft%28+%5Cmathop%7B%5Cmathbb+P%7D+%5BG%28z%29%3Da%5D+-+%5Cfrac+1+%7B2%5En%7D+%5Cright%29%7D&bg=ffffff&fg=000000&s=0&c=20201002) and recall what we said about statistical distance and distance, this is equivalent to proving
and recall what we said about statistical distance and distance, this is equivalent to proving

Recalling that we are working with a partition of into sets , each of size , one would optimistically hope to do so by proving that for every set
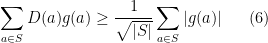
Our proposed distinguisher computes an affine function within each set, so we would need to show that for every there is an affine function such that

Equation (7) is now in a form that is easy to prove via standard Fourier analytic arguments. Here we give a different proof which uses only the fact that affine functions form a pairwise independent family of functions and are closed under complementation.
Lemma 1 Let  be any function, and
be any function, and  be a pairwise independent family of functions
be a pairwise independent family of functions 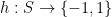 . Then there is a function
. Then there is a function 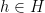 such that
such that
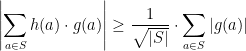
Proof: Using the pairwise independence of  we compute
we compute

so there must exist an such that

and we have

from Cauchy-Schwarz. 

