
Today we will see how to use the analysis of the multiplicative weights algorithm in order to construct pseudorandom sets.
The method will yield constructions that are optimal in terms of the size of the pseudorandom set, but not very efficient, although there is at least one case (getting an “almost pairwise independent” pseudorandom generator) in which the method does something that I am not sure how to replicate with other techniques.
Mostly, the point of this post is to illustrate a concept that will reoccur in more interesting contexts: that we can use an online optimization algorithm in order to construct a combinatorial object satisfying certain desired properties. The idea is to run a game between a “builder” against an “inspector,” in which the inspector runs the online optimization algorithm with the goal of finding a violated property in what the builder is building, and the builder plays the role of the adversary selecting the cost functions, with the advantage that it gets to build a piece of the construction after seeing what property the “inspector” is looking for. By the regret analysis of the online optimization problem, if the builder did well at each round against the inspector, then it will do well also against the “offline optimum” that looks for a violated property after seeing the whole construction. For example, the construction of graph sparsifiers by Allen-Zhu, Liao and Orecchia can be cast in this framework.
(In some other applications, it will be the “builder” that runs the algorithm and the “inspector” who plays the role of the adversary. This will be the case of the Frieze-Kannan weak regularity lemma and of the Impagliazzo hard-core lemma. In those cases we capitalize on the fact that we know that there is a very good offline optimum, and we keep going for as long as the adversary is able to find violated properties in what the builder is constructing. After a sufficiently large number of rounds, the regret experienced by the algorithm would exceed the general regret bound, so the process must terminate in a small number of rounds. I have been told that this is just the “dual view” of what I described in the previous paragraph.)
But, back the pseudorandom sets: if 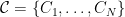

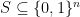

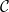
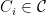
![\displaystyle | \mathop{\mathbb P}_{u \sim \{ 0,1 \}^n} [ C_i (u) =1] - \mathop{\mathbb P}_{s \sim S} [C_i(s) = 1 ] | \leq \epsilon](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7C+%5Cmathop%7B%5Cmathbb+P%7D_%7Bu+%5Csim+%5C%7B+0%2C1+%5C%7D%5En%7D+%5B+C_i+%28u%29+%3D1%5D+-+%5Cmathop%7B%5Cmathbb+P%7D_%7Bs+%5Csim+S%7D+%5BC_i%28s%29+%3D+1+%5D+%7C+%5Cleq+%5Cepsilon+&bg=ffffff&fg=000000&s=0&c=20201002)
That is, sampling uniformly from 
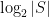


It is easy to use Chernoff bounds and union bounds to argue that there is such a set of size 

We will prove this result (while also providing an “algorithm” for the construction) using multiplicative weights.
First of all, possibly by changing 
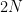
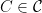

![\displaystyle \forall C\in {\cal C} \ \ \ \mathop{\mathbb P}_{u \sim \{ 0,1 \}^n} [ C (u) =1] - \mathop{\mathbb P}_{s \sim S} [C(s) = 1 ] \geq - \epsilon](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cforall+C%5Cin+%7B%5Ccal+C%7D+%5C+%5C+%5C+%5Cmathop%7B%5Cmathbb+P%7D_%7Bu+%5Csim+%5C%7B+0%2C1+%5C%7D%5En%7D+%5B+C+%28u%29+%3D1%5D+-+%5Cmathop%7B%5Cmathbb+P%7D_%7Bs+%5Csim+S%7D+%5BC%28s%29+%3D+1+%5D+%5Cgeq+-+%5Cepsilon+&bg=ffffff&fg=000000&s=0&c=20201002)
We will make up an “experts” setup in which there is an expert 
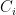



![\displaystyle f_t (x) := \sum_{i=1}^N x(i) \cdot \left( \mathop{\mathbb P}_{u \sim \{ 0,1 \}^n} [ C_i (u) = 1 ] - C_i (s_t) \right)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++f_t+%28x%29+%3A%3D+%5Csum_%7Bi%3D1%7D%5EN+x%28i%29+%5Ccdot+%5Cleft%28+%5Cmathop%7B%5Cmathbb+P%7D_%7Bu+%5Csim+%5C%7B+0%2C1+%5C%7D%5En%7D+%5B+C_i+%28u%29+%3D+1+%5D+-+C_i+%28s_t%29+%5Cright%29+&bg=ffffff&fg=000000&s=0&c=20201002)
where the adversary chooses an 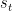
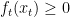
- That such a choice of
- That the cost function is of the form
, where the loss vector
satisfies
, so that the regret after
steps is
;
- That the sequence
of choices by the adversary determines a
-pseudorandom multiset for
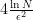
For the first point, note that for a random 
![\displaystyle \mathop{\mathbb E}_{s\sim \{ 0,1 \}^n} \sum_{i=1}^N x_t(i) \cdot \left( \mathop{\mathbb P}_{u \sim \{ 0,1 \}^n} [ C_i (u) = 1 ] - C_i (s) \right) = 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathop%7B%5Cmathbb+E%7D_%7Bs%5Csim+%5C%7B+0%2C1+%5C%7D%5En%7D+%5Csum_%7Bi%3D1%7D%5EN+x_t%28i%29+%5Ccdot+%5Cleft%28+%5Cmathop%7B%5Cmathbb+P%7D_%7Bu+%5Csim+%5C%7B+0%2C1+%5C%7D%5En%7D+%5B+C_i+%28u%29+%3D+1+%5D+-+C_i+%28s%29+%5Cright%29+%3D+0+&bg=ffffff&fg=000000&s=0&c=20201002)
so there is an
![\displaystyle \sum_{i=1}^N x_t(i) \cdot \left( \mathop{\mathbb P}_{u \sim \{ 0,1 \}^n} [ C_i (u) = 1 ] - C_i (s_t) \right) \geq 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csum_%7Bi%3D1%7D%5EN+x_t%28i%29+%5Ccdot+%5Cleft%28+%5Cmathop%7B%5Cmathbb+P%7D_%7Bu+%5Csim+%5C%7B+0%2C1+%5C%7D%5En%7D+%5B+C_i+%28u%29+%3D+1+%5D+-+C_i+%28s_t%29+%5Cright%29+%5Cgeq+0+&bg=ffffff&fg=000000&s=0&c=20201002)
For the second point we just have to inspect the definition, and for the last point we have, by construction
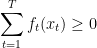
so the regret bound is

which, after dividing by
![\displaystyle \forall i : \ \ \ \frac 1T \sum_{t=1}^T \left( \mathop{\mathbb P}_{u \sim \{ 0,1 \}^n} [ C_i (u) = 1 ] - C_i (s_t) \right) \geq - 2 \sqrt{\frac {\ln n}{T}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cforall+i+%3A+%5C+%5C+%5C+%5Cfrac+1T+%5Csum_%7Bt%3D1%7D%5ET+%5Cleft%28+%5Cmathop%7B%5Cmathbb+P%7D_%7Bu+%5Csim+%5C%7B+0%2C1+%5C%7D%5En%7D+%5B+C_i+%28u%29+%3D+1+%5D+-+C_i+%28s_t%29+%5Cright%29+%5Cgeq+-+2+%5Csqrt%7B%5Cfrac+%7B%5Cln+n%7D%7BT%7D%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \forall i: \ \ \ \ \mathop{\mathbb P}_{u \sim \{ 0,1 \}^n} [ C_i (u) = 1 ] - \Pr_{s\in \{ s_1,\ldots,s_T \} } [C_i (s) = 1 ] \geq - 2 \sqrt{\frac {\ln n}{T}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cforall+i%3A+%5C+%5C+%5C+%5C+%5Cmathop%7B%5Cmathbb+P%7D_%7Bu+%5Csim+%5C%7B+0%2C1+%5C%7D%5En%7D+%5B+C_i+%28u%29+%3D+1+%5D+-+%5CPr_%7Bs%5Cin+%5C%7B+s_1%2C%5Cldots%2Cs_T+%5C%7D+%7D+%5BC_i+%28s%29+%3D+1+%5D+%5Cgeq+-+2+%5Csqrt%7B%5Cfrac+%7B%5Cln+n%7D%7BT%7D%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Consider now the application of constructing a small-support distribution over 




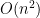


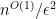





In the Chernoff bound sentence, N should be log(N) (so the number of bits is loglog(N)).
Thanks, I have corrected it
Hello Luca,
can you please explain the averaging argument just after “dividing by T”? Specifically, I do not follow how the part $\sum_{i=1}^N x(i)$ involved in $f_t(x)$ is eliminated.
Cheers,
Elad
Hi Elad, the regret bound holds for every fixed distribution , so I am just looking, for each
, so I am just looking, for each  , at the implication of the regret bound for the cases in which
, at the implication of the regret bound for the cases in which  gives probability 1 to i and probability 0 to the other experts.
gives probability 1 to i and probability 0 to the other experts.
Pingback: Online Optimization Post 7: Matrix Multiplicative Weights Update | in theory