
In this post we return to the generic form of the FTRL online optimization algorithm. If the cost functions are linear, as they will be in all the applications that I plan to talk about, the algorithm is:

where 


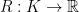
If we have an unconstrained problem, that is, if 

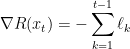
and we can usually both compute
Unfortunately, we are almost always interested in constrained settings, and then it becomes difficult both to compute
A very nice special case happens when the regularizer 

We swept this point under the rug when we studied FTRL with negative-entropy regularizer in the settings of experts, in which 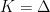

Another important special case occurs when the regularizer 


Then we have the closed-form solution 
![{K= [0,1]^n}](https://s0.wp.com/latex.php?latex=%7BK%3D+%5B0%2C1%5D%5En%7D&bg=ffffff&fg=000000&s=0&c=20201002)
As we will see today, this approach of solving the unconstrained problem and then projecting on
To define the Bregman projection, we will first define the Bregman divergence with respect to the regularizer 



Unfortunately, it is not so easy to reason about Bregman projections either, but the notion of Bregman divergence offers a way to reinterpret the FTRL algorithm from another point of view, called mirror descent. Via this reinterpretation, we will prove the regret bound

which carries the intuition that the regret comes from a combination of the “distance” of our initial solution from the offline optimum and of the “stability” of the algorithm, that is, the “distance” between consecutive soltuions. Nicely, the above bound measures both quantities using the same “distance” function.
1. Bregman Divergence and Bregman Projection
For a strictly convex function 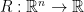
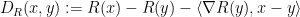
that is, the difference between the value of 




Now we show that, assuming that 


The proof is very simple. The optimum of the unconstrained optimization problem is the unique 
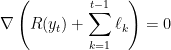
that is, the unique

On the other hand,

that is,

where the second equality above follows from the fact that two functions that differ by a constant have the same optimal solutions.
Indeed we see that the above “decoupled” characterization of the FTRL algorithm would have worked for any definition of a function of the form

and that our particular choice of what “stuff dependent only on 
Note that, in all of the above, we can replace 

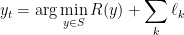
is the unique

and everything else follows analogously.
2. Examples
2.1. Bregman Divergence of Length-Squared
If 

so Bregman divergence is distance-squared, and Bregman projection is just (Euclidean) projection.
2.2. Bregman Divergence of Negative Entropy
If, for 
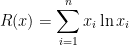
then the associated Bregman divergence is the generalized KL divergence.

where 

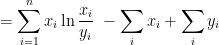
Note that, if 
3. Mirror Descent
We now introduce a new perspective on FTRL.
In the unconstrained setting, if 
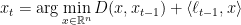
The idea is that we want to find a solution that is good for the past loss functions, but that does not “overfit” too much. If, in past steps, 
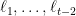

Theorem 1 Initialized with
, the unconstrained mirror descent algorithm is identical to FTRL with regularizer
Proof: We will proceed by induction on 
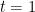


First, we note that the function 
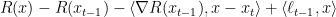
and so it is a sum of a strictly convex function 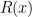

and so
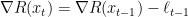
and, using the inductive hypothesis, we have
as desired.

In the constrained case, there are two variants of mirror descent. Using the terminology from Elad Hazan’s survey, agile mirror descent is the natural generalization of the unconstrained algorithm:
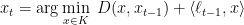
Following the same steps as the proof in the previous section, it is possible to show that agile mirror descent is equivalent to solving, at each iteration, the “decoupled” optimization problems

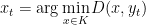
That is, we can first solve the unconstrained problem and then project on 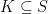
The lazy mirror descent algorithm has the update rule
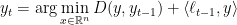
The initialization is

Fact 2 Lazy mirror descent is equivalent to FTRL.
Proof: The solutions
What about agile mirror descent? In certain special cases it is equivalent to lazy mirror descent, and hence to FTRL, but it usually leads to a different set of solutions.
We will provide an analysis of lazy mirror descent, but first we will give an analysis of the regret of unconstrained FTRL in terms of Bregman divergence, which will be the model on which we will build the proof for the constrained case.
4. A Regret Bound for FTRL in Terms of Bregman Divergence
In this section we prove the following regret bound.
Theorem 3 Unconstrained FTRL with regularizer
where

We will take the mirror descent view of unconstrained FTRL, so that


We proved that

This means that we can rewrite the regret suffered at step


and the theorem follows by adding up the above expression for 

Unfortunately I have no geometric intuition about the above identity, although, as you can check yourself, the algebra works neatly.
5. A Regret Bound for Agile Mirror Descent
In this section we prove the following generalization of the regret bound from the previous section.
Theorem 4 Agile mirror descent satisfies the regret bound
The first part of the update rule of agile mirror descent is
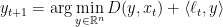
and, following steps that we have already carried out before, 
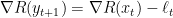
This means that we can rewrite the regret suffered at step

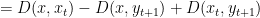
where the same mystery cancellations as before make the above identity true.
Now I will wield another piece of magic, and I will state without proof the following fact about Bregman projections
Lemma 5 If
and
is the Bregman projection on
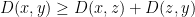
That is, if we think of
In particular, the above lemma gives us
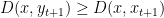
and so
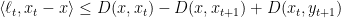
Now summing over

Teşekkür ederim.
http://www.webdunya.com
Pingback: Online Optimization Post 7: Matrix Multiplicative Weights Update | in theory