In which we define and analyze the zig-zag graph product.
1. Replacement Product and Zig-Zag Product
In the previous lecture, we claimed it is possible to “combine” a  -regular graph on
-regular graph on  vertices and a -regular graph on
vertices and a -regular graph on  vertices to obtain a
vertices to obtain a 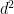 -regular graph on
-regular graph on 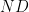 vertices which is a good expander if the two starting graphs are. Let the two starting graphs be denoted by
vertices which is a good expander if the two starting graphs are. Let the two starting graphs be denoted by  and
and  respectively. Then, the resulting graph, called the zig-zag product of the two graphs is denoted by
respectively. Then, the resulting graph, called the zig-zag product of the two graphs is denoted by 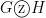 .
.
Using 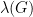 to denote the eigenvalue with the second-largest absolute value for a graph , we claimed that if
to denote the eigenvalue with the second-largest absolute value for a graph , we claimed that if  and
and  , then
, then 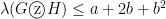 . In this lecture we shall describe the construction for the zig-zag product and prove this claim.
. In this lecture we shall describe the construction for the zig-zag product and prove this claim.
2. Replacement product of two graphs
We first describe a simpler product for a “small” -regular graph on vertices (denoted by ) and a “large” -regular graph on vertices (denoted by ). Assume that for each vertex of , there is some ordering on its neighbors. Then we construct the replacement product (see figure)  as follows:
as follows:
- Replace each vertex of with a copy of (henceforth called a cloud). For
 , let
, let  denote the
denote the  vertex in the
vertex in the 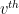 cloud.
cloud.
- Let
 be such that
be such that  is the
is the  -th neighbor of
-th neighbor of  and is the
and is the  -th neighbor of . Then
-th neighbor of . Then  . Also, if
. Also, if  , then
, then  .
.
Note that the replacement product constructed as above has vertices and is  -regular.
-regular.

3. Zig-zag product of two graphs
Given two graphs and as above, the zig-zag product 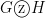 is constructed as follows (see figure):
is constructed as follows (see figure):
- The vertex set
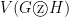 is the same as in the case of the replacement product.
is the same as in the case of the replacement product.
-
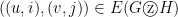 if there exist
if there exist  and
and  such that
such that 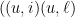 ,
,  and
and  are in
are in 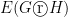 i.e.
i.e. 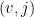 can be reached from
can be reached from 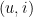 by taking a step in the first cloud, then a step between the clouds and then a step in the second cloud (hence the name!).
by taking a step in the first cloud, then a step between the clouds and then a step in the second cloud (hence the name!).

It is easy to see that the zig-zag product is a -regular graph on vertices.
Let ![{M \in {\mathbb R}^{([N] \times [D]) \times ([N] \times [D])}}](https://s0.wp.com/latex.php?latex=%7BM+%5Cin+%7B%5Cmathbb+R%7D%5E%7B%28%5BN%5D+%5Ctimes+%5BD%5D%29+%5Ctimes+%28%5BN%5D+%5Ctimes+%5BD%5D%29%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) be the normalized adjacency matrix of . Using the fact that each edge in is made up of three steps in , we can write
be the normalized adjacency matrix of . Using the fact that each edge in is made up of three steps in , we can write  as
as 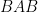 , where
, where
![\displaystyle \begin{array}{rcl} B[(u,i),(v,j)] = \left\{ \begin{array}{ll} 0 & if~u\neq v \\ M_H[i,j] & if~u=v \\ \end{array} \right. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++B%5B%28u%2Ci%29%2C%28v%2Cj%29%5D+%3D+%5Cleft%5C%7B+%5Cbegin%7Barray%7D%7Bll%7D+0+%26+if%7Eu%5Cneq+v+%5C%5C+M_H%5Bi%2Cj%5D+%26+if%7Eu%3Dv+%5C%5C+%5Cend%7Barray%7D+%5Cright.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
And ![{A[(u,i),(v,j)]=1}](https://s0.wp.com/latex.php?latex=%7BA%5B%28u%2Ci%29%2C%28v%2Cj%29%5D%3D1%7D&bg=ffffff&fg=000000&s=0&c=20201002) if is the -th neighbor of and is the -th neighbor of , and
if is the -th neighbor of and is the -th neighbor of , and ![{A[(u,i),(v,j)]=0}](https://s0.wp.com/latex.php?latex=%7BA%5B%28u%2Ci%29%2C%28v%2Cj%29%5D%3D0%7D&bg=ffffff&fg=000000&s=0&c=20201002) otherwise.
otherwise.
Note that  is the adjacency matrix for a matching and is hence a permutation matrix.
is the adjacency matrix for a matching and is hence a permutation matrix.
4. Preliminaries on Matrix Norms
Recall that, instead of bounding 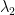 , we will bound the following parameter (thus proving a stronger result).
, we will bound the following parameter (thus proving a stronger result).
Definition 1 Let be the normalized adjacency matrix of a graph 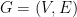 , and
, and  be its eigenvalues with multiplicities. Then we use the notation
be its eigenvalues with multiplicities. Then we use the notation

The parameter  has the following equivalent characterizations.
has the following equivalent characterizations.
Fact 2
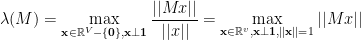
Another equivalent characterization, which will be useful in several contexts, can be given using the following matrix norm.
Definition 3 (Spectral Norm) The spectral norm of a matrix 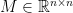 is defined as
is defined as

If is symmetric with eigenvalues 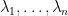 , then the spectral norm is
, then the spectral norm is  . Note that is indeed a norm, that is, for every two square real matrices
. Note that is indeed a norm, that is, for every two square real matrices  we have
we have  and for every matrix and scalar
and for every matrix and scalar  we have
we have  . In addition, it has the following useful property:
. In addition, it has the following useful property:
Fact 4 For every two matrices  we have
we have

Proof: For every vector  we have
we have

where the first inequality is due to the fact that  for every vector
for every vector  , and the second inequality is due to the fact that
, and the second inequality is due to the fact that  . So we have
. So we have


We can use the spectral norm to provide another characterization of the parameter 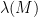 of the normalized adjacency matrix of a graph.
of the normalized adjacency matrix of a graph.
Lemma 5 Let be a regular graph and be its normalized adjacency matrix. Then

where  is the matrix with a 1 in each entry.
is the matrix with a 1 in each entry.
Proof: Let  be the eigenvalues of and
be the eigenvalues of and  ,
,  ,
, 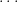 ,
, 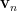 a corresponding system of orthonormal eigenvector. Then we can write
a corresponding system of orthonormal eigenvector. Then we can write

Noting that  , we have
, we have

and so  is also a system of eigenvectors for
is also a system of eigenvectors for  , with corresponding eigenvalues
, with corresponding eigenvalues  , meaning that
, meaning that
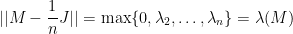
The above lemma has several applications. It states that, according to a certain definition of distance, when a graph is a good expander then it is close to a clique. (The matrix 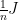 is the normalized adjacency matrix of a clique with self-loops.) The proof of several results about expanders is based on noticing that the result is trivial for cliques, and then on “approximating” the given expander by a clique using the above lemma.
is the normalized adjacency matrix of a clique with self-loops.) The proof of several results about expanders is based on noticing that the result is trivial for cliques, and then on “approximating” the given expander by a clique using the above lemma.
We need one more definition before we can continue with the analysis of the zig-zag graph product.
Definition 6 (Tensor Product) Let  and
and 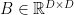 be two matrices. Then
be two matrices. Then 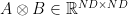 is a matrix whose rows and columns are indexed by pairs
is a matrix whose rows and columns are indexed by pairs ![{(u,i)\in [N] \times [D]}](https://s0.wp.com/latex.php?latex=%7B%28u%2Ci%29%5Cin+%5BN%5D+%5Ctimes+%5BD%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) such that
such that

For example  is a block-diagonal matrix in which every block is a copy of .
is a block-diagonal matrix in which every block is a copy of .
5. Analysis of the Zig-Zag Product
Suppose that and are identical cliques with self-loops, that is, are both  -regular graphs with self-loops. Then the zig-zag product of and is well-defined, because the degree of is equal to the number of vertices of . The resulting graph is a
-regular graphs with self-loops. Then the zig-zag product of and is well-defined, because the degree of is equal to the number of vertices of . The resulting graph is a 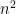 -regular graph with vertices, and an inspection of the definitions reveals that is indeed a clique (with self-loops) with vertices.
-regular graph with vertices, and an inspection of the definitions reveals that is indeed a clique (with self-loops) with vertices.
The intuition for our analysis is that we want to show that the zig-zag graph product “preserves” distances measured in the matrix norm, and so if is close (in matrix norm) to a clique and is close to a clique, then is close to the zig-zag product of two cliques, that is, to a clique. (Strictly speaking, what we just said does not make sense, because we cannot take the zig-zag product of the clique that is close to and of the clique that is close to, because they do not have the right degree and number of vertices. The proof, however, follows quite closely this intuition.)
Theorem 7 If 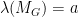 and
and  , then
, then

Proof: Let be the normalized adjacency matrix of , and let  be a unit vector such that
be a unit vector such that 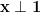 and
and

Recall that we defined a decomposition

where is a permutation matrix, and 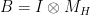 . Let us write
. Let us write  , then
, then  . Let us call
. Let us call  and
and  .
.
First, we argue that the matrix norm of  is small. Take any vector
is small. Take any vector  and write is as
and write is as  , where, for each
, where, for each ![{u\in [N]}](https://s0.wp.com/latex.php?latex=%7Bu%5Cin+%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ,
, 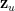 is the -dimensional restriction of to the coordinates in the cloud of . Then
is the -dimensional restriction of to the coordinates in the cloud of . Then

and so we have
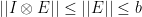
Then we have


and so, using the triangle inequality and the property of the matrix norm, we have
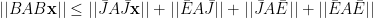
where


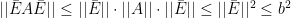
It remains to prove that 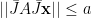 . If we let
. If we let  be the adjacency matrix of , then we can see that
be the adjacency matrix of , then we can see that
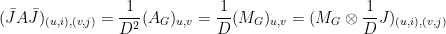
That is,
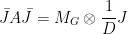
Finally, we write  , where
, where 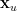 is the -dimensional vector of entries corresponding to the cloud of , we call
is the -dimensional vector of entries corresponding to the cloud of , we call  , and we note that, by Cauchy-Schwarz:
, and we note that, by Cauchy-Schwarz:
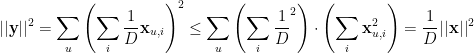
The final calculation is:


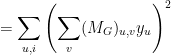





gilbert arenas drew brees
Pingback: clearing doubt over a definition - MathHub
Pingback: Greatest Hits of TCS: SL=L | On The Shoulders Of Windmills
Pingback: a basic doubt about definition in graph theory – Math Solution